LLM RAGとは?情報漏洩を防ぐ企業向けローカル環境構築5ステップ【2026年版】
企業がLLMを安全に活用するために欠かせない「RAG(検索拡張生成)」と「ローカルLLM」。社内の機密データを外部に漏らさずに独自のAIを構築する仕組みと、ビジネス実装に向けた具体的なステップを解説します。
企業のDX推進において、生成AIの活用は不可欠ですが、情報漏洩リスクやデータ連携の課題が導入の障壁となるケースは少なくありません。特に機密性の高い社内データを扱う場合、安全な環境構築が最優先事項です。本記事では、この課題を解決する LLM RAG (Retrieval-Augmented Generation)の仕組みと、情報漏洩を防ぐためのローカル環境構築に焦点を当てます。この記事を読むことで、企業が安全にLLMを活用し、業務効率化と競争力強化を実現するための実践的なノウハウと具体的な導入・運用ポイントを習得できます。
LLM RAGの基本アーキテクチャと仕組み
企業が安全かつ効果的に生成AIを活用するためには、まずはLLMの仕組みとRAG(Retrieval-Augmented Generation)の基本アーキテクチャを正しく理解し、社内データとの連携方法を整理することが不可欠です。
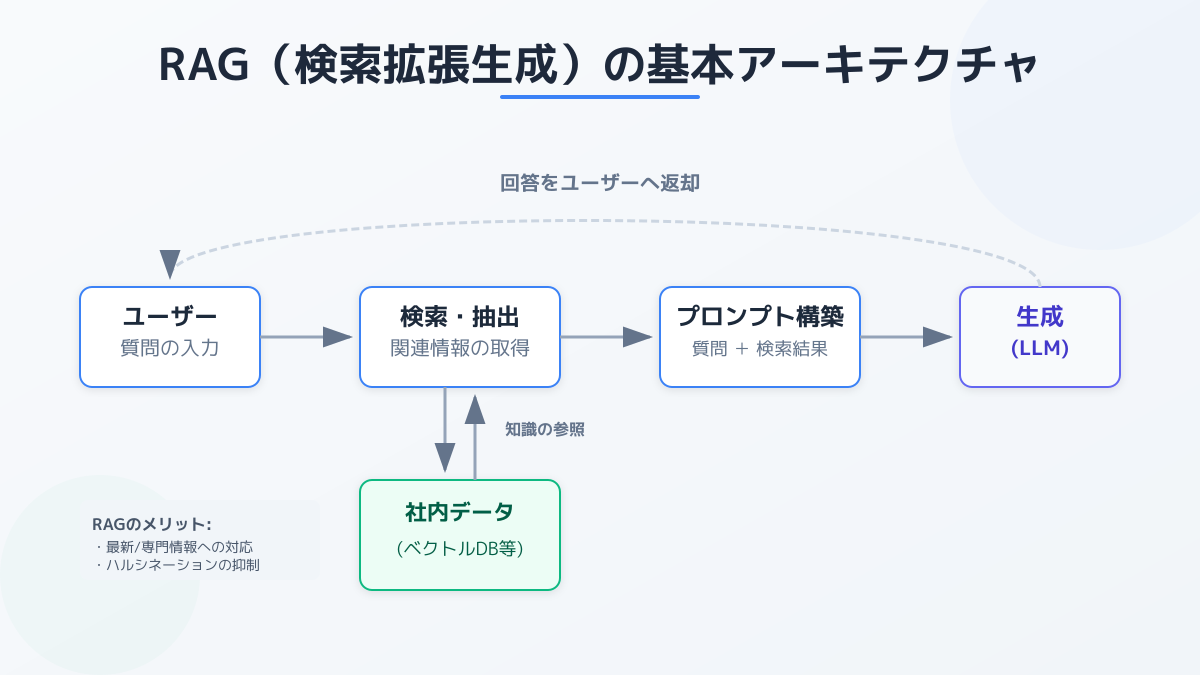
RAGの基本事項と導入の判断ポイント
RAGは、ユーザーの質問に対して自社の独自データベースから関連情報を検索し、その結果をプロンプトに組み込んでLLM(大規模言語モデル)に回答を生成させる技術です。これにより、LLM単体では答えられない社内規定や最新の業務データに基づいた、正確で根拠のある回答が可能になります。
導入時における最大の判断ポイントは、どのデータを外部のAPI(クラウド型LLM)に渡し、どのデータをローカル環境に留めるかという「データ分類とセキュリティ要件の定義」です。情報漏洩を防ぐためには、機密性の高い顧客情報や未公開の技術データを扱う場合、オンプレミス環境でのローカルLLM構築を前提としたアーキテクチャ設計を検討する必要があります。
現場で運用する際の注意点
LLM RAGを現場で運用する際の注意点として、検索フェーズ(Retrieval)の精度低下が、結果的にハルシネーション(もっともらしい嘘)を引き起こすリスクが挙げられます。これを防ぐためには、単にシステムを構築して終わりではなく、社内ドキュメントへの適切なメタデータ付与や、ベクトルデータベースの定期的なチューニングといった継続的なデータ整備が求められます。入力されるデータの品質が、そのまま出力される回答の品質に直結します。
要点の整理とプロジェクト化
LLM RAGの導入は、単なるITツールの追加ではなく、社内のナレッジ共有プロセスを根本から変革する取り組みです。そのため、技術的な要件を整理するだけでなく、ビジネス上の目的や期待される費用対効果を明確にすることがプロジェクト成功の鍵となります。
導入に向けた社内稟議や企画立案を進める際は、【完全版】新規事業の企画書の書き方|承認される構成とプレゼン資料例 を参考に、経営層や部門リーダーが納得するロジックと体制図を組み立てることをおすすめします。
ローカル環境でのセキュリティ確保
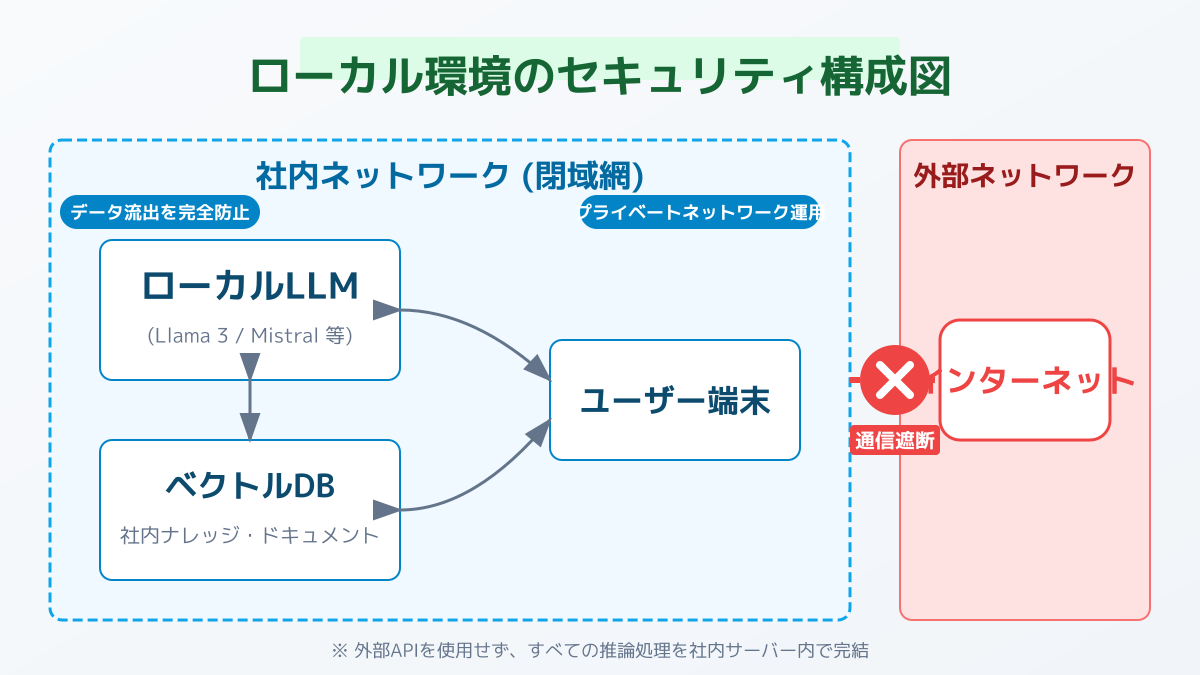
企業がAIを活用する上で、機密データの保護は最重要課題の一つです。自社データを安全に連携させるための環境構築とセキュリティ戦略について整理します。
情報漏洩を防ぐローカルLLM構築のステップ
一般的なパブリッククラウドのAPIを利用した場合、入力したプロンプトや社内データが外部サーバーへ送信されるため、コンプライアンス上の懸念が生じます。そこで有効なのが、社内ネットワークから出ないLLMのローカル環境での構築です。
具体的な手順としては、以下の3ステップが基本となります。
- オープンソースモデルの選定: Meta社の「Llama 3」やGoogleの「Gemma」など、商用利用が可能で自社の要件に合ったモデルを選びます。日本語の処理能力や、想定されるハードウェアリソース(VRAMの容量など)を基準に評価します。
- 実行環境ツールの導入: 現場のPCや社内サーバーで簡単にLLMを動かすため、「Ollama」や「LM Studio」などのローカル実行ツールを導入し、複雑な環境構築を簡略化します。たとえば、Ollamaであればコマンドラインから
ollama run llama3と入力するだけで、すぐに検証を開始できます。 - 社内データとの連携(RAGの実装): 「LangChain」や「LlamaIndex」などのフレームワークを活用し、ローカル環境のLLMと社内データベースを連携させます。ここで「Chroma」や「FAISS」といったベクトルデータベースを用いて社内ドキュメントの検索基盤を構築し、RAGのパイプラインを完成させます。
この構成により、外部ネットワークとの通信を遮断した強力な情報漏洩対策が可能になります。
現場運用の注意点とインフラ要件
ローカル環境でLLM RAGを運用する場合、現場での継続的なインフラ管理が課題となります。モデルを快適に動作させるためには、十分なメモリを搭載したGPUサーバー(例:VRAM 24GB以上を搭載したNVIDIA RTXシリーズなど)や高スペックなローカルPCの調達、さらにはオープンソースモデルの定期的なアップデート作業が必要です。また、回答の正確性を維持するためには、社内規程の更新に合わせてRAGが参照するデータベースを常に最新状態に保つ運用体制が不可欠です。
要点を整理すると、高度なセキュリティ要件とインフラ運用負荷のバランスをどう最適化するかが成功の鍵を握ります。情報漏洩リスクが極めて高い法務や人事などの領域ではローカル環境を優先し、一般的な業務効率化にはセキュアなクラウドを利用するといった使い分けが現実的です。こうした全社的なAI導入方針を策定する際は、IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイントを活用し、自社のITインフラ全体とビジネス目標の整合性を図ることを推奨します。
ハイブリッド構成によるセキュリティと利便性の両立
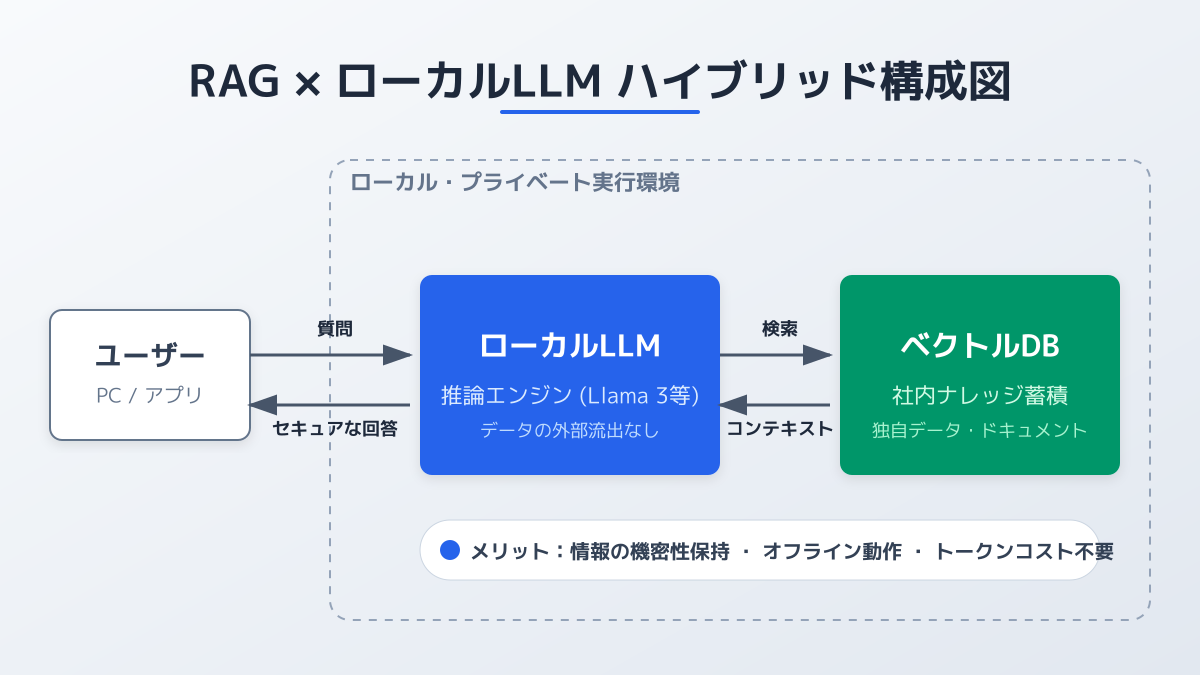
企業がLLM RAGを導入する際、機密情報の取り扱いは最も重要な課題です。クラウド上のLLMに社外秘データを渡す情報漏洩リスクを排除するため、自社専用のサーバーや端末内で完結する、LLMのローカル環境でのRAG構築が注目されています。ここでは、セキュリティと利便性を両立させるための基本事項と判断ポイントを整理します。
ハイブリッド構成を導入する判断基準
すべての業務をローカル環境で処理する必要はありません。インフラコストや処理速度とのバランスを取るため、クラウドとローカルを使い分けるハイブリッド構成が有効です。
導入を判断する際は、扱うデータの機密レベルを明確な基準にします。たとえば、一般的な業務マニュアルや社内規定の検索には高速で高性能なクラウド型LLMを使用し、顧客の個人情報や未公開の財務データ、独自の技術文書を参照する業務にはローカル環境のLLMを割り当てるといった切り分けが必要です。これにより、コストを最適化しながらセキュアな環境を構築できます。
現場での運用と定着に向けた注意点
ローカル環境でLLM RAGを運用する場合、クラウド型と比較して回答の生成速度が落ちる、あるいはマシンスペックへの依存度が高まる傾向があります。現場の業務効率を下げないためには、検索対象となるデータベースの軽量化や、特定の業務用途に特化した小規模なLLMの選定が不可欠です。
また、回答の精度を継続的に維持するためには、参照元となる社内ドキュメントの定期的な更新と、AIの回答に対する現場からのフィードバックループを回す運用体制が求められます。システムを導入して終わりではなく、現場の実務担当者が使いやすいようチューニングを続けることが重要です。
セキュリティと利便性の両立
要点を整理すると、安全かつ実用的なLLM RAGの構築には、データの機密性に応じた環境の使い分けが鍵となります。情報漏洩リスクを最小限に抑えつつ、現場がストレスなく活用できるハイブリッドなインフラを整備することが、企業のAI活用を成功に導く最大のポイントです。
システム導入後の運用体制と継続的な改善
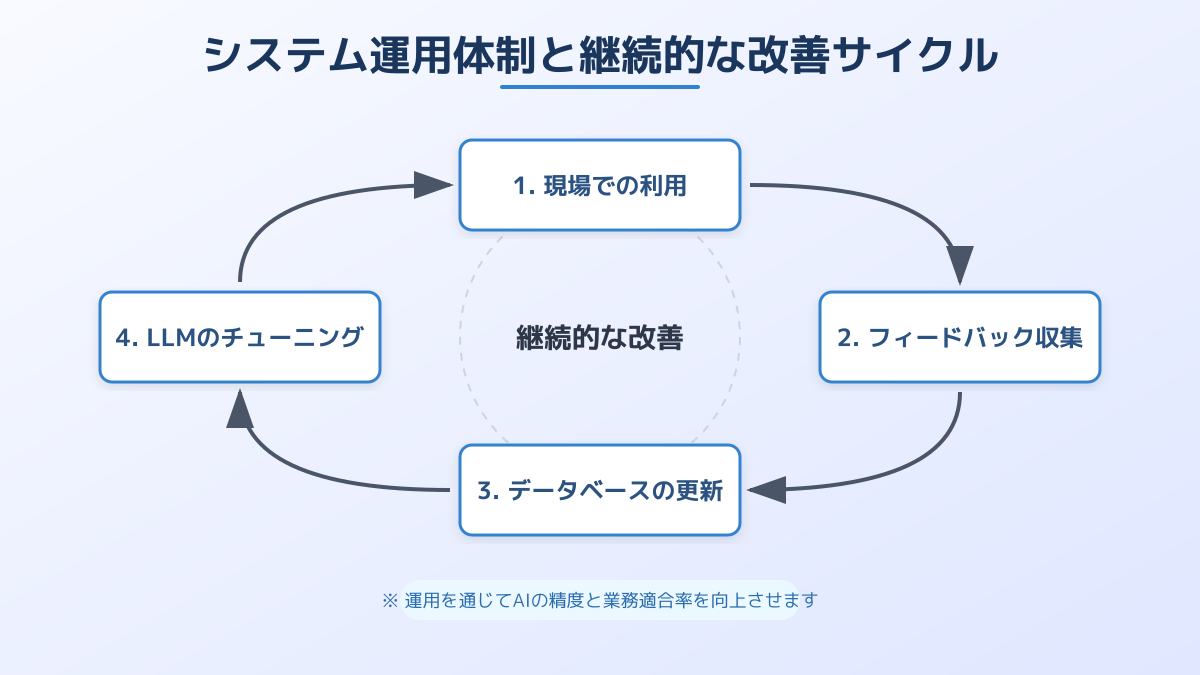
LLM RAGを企業に定着させるためには、システム構築後の運用体制と継続的な改善プロセスが鍵を握ります。独自の社内データを活用して精度の高い回答を生成する仕組みを構築しても、現場の業務フローにスムーズに組み込まれなければ、期待する投資対効果は得られません。テクノロジーの導入だけでなく、それを使う「人」と「組織」の準備を整えることが重要です。
導入判断とユースケースの具体化
本格的なLLM導入に踏み切る際の判断ポイントは、現場の課題解決に直結する ユースケースが明確に定義できているか という点にあります。たとえば、社内規定の検索、ヘルプデスク業務の効率化、過去の提案書の要約など、特定の業務に絞ってスモールスタートで効果測定を行うことが推奨されます。
新しいシステムを導入して終わりにするのではなく、作業時間の削減率や回答の正確性など、どのような指標で業務効率化を評価するのかを事前に具体化しておく必要があります。
現場運用におけるセキュリティと品質管理
実際に現場で運用する際の最大の注意点は、情報漏洩リスクへの対応とハルシネーション(AIの幻覚)の管理です。企業独自の機密データを扱う環境では、ローカル環境での処理や、部署ごとのアクセス権限の厳格な管理が不可欠です。
また、AIが出力した回答をそのまま外部へ送信するのではなく、必ず人間が事実確認を行う ヒューマンインザループ のプロセスを業務フローに組み込む必要があります。現場の担当者が迷わず安全に使えるよう、具体的なプロンプトの入力例や禁止事項を定めたガイドラインを策定することが求められます。
運用サイクルの確立と要点の整理
ここまでの要点を押さえると、システムの構築と現場の運用体制は両輪で進めるべきだということが分かります。効果的なLLM活用術を社内ポータルや定例会議で共有し、定期的な勉強会やフィードバックループを構築することで、システム全体の精度と利用率が向上します。
現場のリアルな声を拾い上げ、検索対象となるデータベースの品質を継続的にアップデートしていく運用サイクルを確立することが、LLM RAGを成功に導く核心です。
セキュリティとデータガバナンスの確立

企業がLLM RAGを導入する際、最も慎重に検討すべきポイントの1つがセキュリティとデータガバナンスの確立です。社内の機密情報や顧客データを直接扱う仕組みであるため、情報漏洩を防ぐ堅牢な運用体制が欠かせません。ここでは、安全な運用に向けた基本事項と判断基準を整理します。
セキュリティとデータガバナンスの基本事項
RAGにおけるセキュリティの基本は、AIが参照する社内データベースへの厳密な アクセス制御 です。すべての従業員が全データにアクセスできる状態は、情報漏洩のリスクを大幅に高めます。そのため、役職や所属部門に応じた適切な権限設定が求められます。
また、データガバナンスの観点からは、どのような情報が検索対象として登録されているかを常に把握しておく必要があります。古い情報や不要になった機密データが残ったままにならないよう、定期的な データの棚卸し と更新を行う管理体制を構築することが重要です。
導入環境の判断ポイント
本システムを構築する際の重要な判断ポイントは、クラウド環境を利用するか、ローカル環境(オンプレミス)を構築するかというインフラの選定です。
一般的なクラウド型のLLMは利便性が高い一方で、入力データがモデルの再学習に利用される懸念があります。機密性の高いデータを扱う場合は、データが学習に利用されないエンタープライズ向けサービスを選択する必要があります。さらに厳密なセキュリティが求められる場合は、自社ネットワーク内にクローズドなローカル環境を構築し、外部と完全に遮断するアプローチが有効です。
現場で運用する際の注意点
現場で運用する際の注意点として、システム的な防御だけでなく、利用する従業員のリテラシー向上が不可欠です。個人情報や未公開の財務情報など、システムに入力してはならないデータの基準を 社内ガイドライン として明確化し、継続的な教育を実施する必要があります。
要点を整理すると、強固なアクセス制御によるデータ保護、要件に応じた適切な導入環境の選定、そして現場における運用ルールの徹底という3点に集約されます。これらを総合的に満たすことで、企業はリスクを最小限に抑えながら、安全に業務変革を推進できます。
運用フェーズにおける継続的な評価と改善
企業環境でLLM RAGを導入したのち、最も重要になるのが運用フェーズにおける継続的な評価と改善です。ここでは、システムを形骸化させないための基本事項と現場での注意点を整理します。
運用時の判断ポイントと注意点
LLM RAGの回答精度は、参照する社内データベースの質と鮮度に大きく依存します。そのため、どのタイミングで新しい社内ドキュメントを追加し、古い情報を破棄するかの 更新ルールの策定 が重要な判断ポイントとなります。情報が古いまま運用を続けると、ハルシネーション(もっともらしい嘘)を誘発するリスクが高まります。
また、現場で運用する際の注意点として、ユーザーからのフィードバックループを構築することが挙げられます。出力された回答に対して、現場の担当者が「役に立ったか」「事実誤認がないか」を簡単に評価できる仕組みを設けてください。この評価データをもとに、検索アルゴリズムの調整やプロンプトの改善を定期的に実施することが、実用性を維持する鍵となります。
要点を整理すると、システムを成功させるためには、構築して終わりではなく、データの鮮度管理とユーザー評価に基づく継続的なチューニングが不可欠です。現場の業務プロセスに合わせた運用体制を整えることで、はじめて持続的な業務効率化が実現します。
まとめ
本記事では、企業が安全かつ効果的に生成AIを活用するための LLM RAG 構築と、情報漏洩を防ぐローカル環境の実践ガイドを解説しました。主要なポイントは以下の通りです。
- LLM RAGの仕組み理解: RAGの基本アーキテクチャと社内データ連携の重要性を把握し、ビジネス目的を明確にすることが成功の鍵です。
- ローカル環境でのセキュリティ確保: 機密データを保護するため、社内ネットワーク内で完結するLLMローカル環境の構築が有効です。
- ハイブリッド構成の検討: セキュリティと利便性を両立させるため、データの機密性に応じたクラウドとローカルの使い分けが現実的です。
- 運用体制と継続的改善: システム導入後も、ユースケースの具体化、フィードバックループの構築、データベースの更新を通じて精度を向上させることが不可欠です。
- 強固なデータガバナンス: アクセス制御、社内ガイドラインの策定、従業員教育により、情報漏洩リスクを最小限に抑えます。
これらのポイントを踏まえ、自社の状況に合わせた最適なLLM RAG戦略を策定することで、企業はリスクを管理しながら生成AIの恩恵を最大限に享受し、持続的な成長を実現できるでしょう。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事
システム運用とは?保守との違いと属人化を防ぐ6つのポイント【2026年版】
企業のITインフラを支えるシステム運用とシステム保守。似て非なる両者の業務内容の違いを明確にし、日々の運用管理で発生しやすい属人化やヒューマンエラーを防ぐための体制構築、自動化のポイントを解説します。
プロセスマイニングとは?DX推進を成功に導く8つのポイント【2026年版】
企業の業務プロセス改善において、担当者の感覚に頼らないデータドリブンなアプローチとして注目される「プロセスマイニング」。システム上のログデータを活用して真のボトルネックを特定する仕組みや、DX推進における具体的な導入メリットを解説します。
データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。

UI/UXデザイナーとは?仕事内容・年収・Webデザイナーとの違い【2026年版】
企業のDX推進において欠かせない「UI/UXデザイナー」。本記事では、UI/UXデザイナーとは何か、Webデザイナーとの業務範囲やスキルの決定的な違いを解説します。また、UXリサーチやデータ分析など、DX時代に求められる7つの具体的な役割について、実践的な例を交えて詳しく紹介します。

LTV(顧客生涯価値)とは?計算式と最大化する5つの施策【2026年版】
サブスクリプションやSaaSビジネスで最も重視される指標の1つ「LTV(顧客生涯価値)」。LTVの基本概念から正しい計算方法、マーケティング施策を通じてLTVを最大化するための実践的なアプローチを解説します。

BPO事業とは?市場規模と戦略的活用で変革を加速する実践ガイド【2026年版】
年々市場規模が拡大しているBPO事業。そもそもBPO事業とはどのようなビジネスモデルなのか、提供されるサービスの種類や急成長の背景を解説します。また、外部委託を検討する企業に向けて、自社の課題に最適なBPOサービスの選び方や、ビジネス変革を加速させた具体的な成功事例を提示します。