データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。
多くの企業がデータ活用やAI導入を推進する中で、データの品質は成果を左右する重要な要素です。不正確なデータはAIの予測精度を低下させ、誤った意思決定につながるリスクがあります。データの真の価値を引き出し、AIのポテンシャルを最大限に引き出すためには、体系的なデータクレンジングが不可欠です。本記事では、データクレンジングの基本概念から、AIの精度を劇的に高めるための5つの具体的なやり方、そして継続的な運用ノウハウまでを網羅的に解説します。データドリブン経営を目指すビジネスリーダーや実務担当者にとって、実践的な指針となるでしょう。
データクレンジングとは?AI活用における目的と重要性
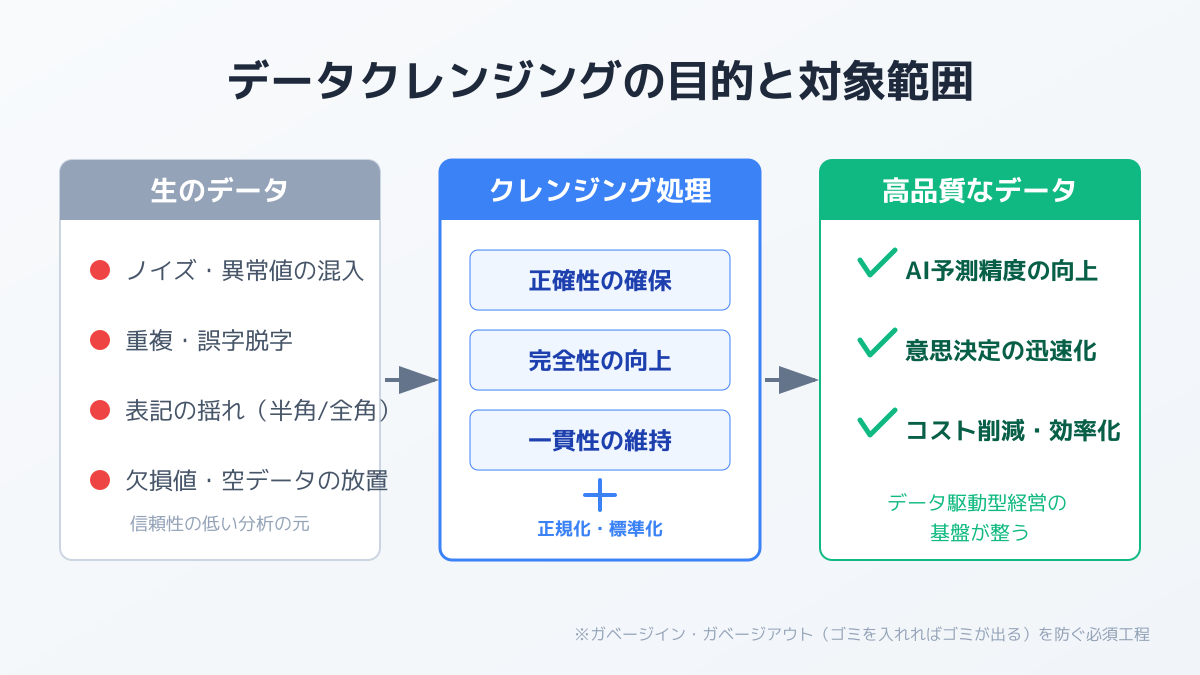
データクレンジングとは、データベース内に存在する不正確なデータ、重複データ、欠損値などを特定し、修正または削除することでデータの品質を高めるプロセスのことです。英語では「Data Cleansing」や「Data Scrubbing」と呼ばれ、データ分析やAIモデル構築の前処理として極めて重要な役割を担います。
データ活用の基盤を構築するうえで、最初のステップとなるのが目的と対象範囲の明確化です。単にデータを綺麗に整えること自体を目的化してしまうと、現場の工数ばかりが膨らみ、期待するビジネス成果につながりません。
まずは、何のためにデータを整備するのかという基本事項を整理します。たとえば、データクレンジングでAIの予測精度を劇的に高めたいのか、あるいはマーケティング部門が持つ顧客リストの重複を排除して業務効率化を図りたいのかによって、必要なデータの粒度や品質基準は大きく変わります。とくに機械学習の学習用データとして用いる場合、入力データのノイズや欠損値がモデルの出力結果に直結するため、より厳密な処理が求められます。
目的が定まったら、次にクレンジングの判断ポイントを具体化します。企業内に蓄積されたすべてのデータを完璧な状態にするのは現実的ではありません。そのため、「正確性」「完全性」「一貫性」「鮮度」といった指標のなかから、今回のプロジェクトにおいてどの要素を最優先するかを決定します。データ戦略を立案する際は、自社のビジネス目標とIT施策を連動させることが不可欠です。全体像の設計については、IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイント も併せて参考にしてください。
やり方①:欠損値・異常値の適切な処理

具体的なクレンジングの手順を検討する際、現場で最初につまずきやすいのが「欠損値(データが存在しない状態)」と「異常値(通常の範囲から大きく外れた値)」の扱いです。これらを一律に削除してしまうと、AIの予測モデル構築に必要な重要な特徴量まで失う危険性があります。
欠損値の処理においては、平均値や中央値で数値を補完する手法が一般的ですが、データの性質によっては「欠損していること自体」が意味を持つケースもあります。 たとえば、アンケートデータにおける「任意回答項目の空白」は、システムエラーによる欠損ではなく「ユーザーが意図的に回答を避けた」という重要なシグナルです。これを平均値で埋めてしまうと、AIは誤った傾向を学習してしまいます。そのため、代替データで補完するのか、そのレコード自体を除外するのかを、自社のビジネス要件と照らし合わせて慎重に決定しなければなりません。
また、異常値の処理に関しても同様です。たとえば、小売業の顧客データに「年齢:150歳」という値があった場合、これは明らかな入力ミスであり、平均値に丸めるか除外する処理が必要です。一方で、クレジットカードの決済データにおいて「普段の100倍の金額の利用」があった場合、これは異常値ですが削除してはいけません。不正利用を検知するAIモデルにとっては最も重要な学習データとなるためです。
こうした例外データへの対応ルールを明確化し、事業部門とIT部門が連携して判断基準を具体化しておくことが重要です。現場のドメイン知識(業務知識)を活用し、データの発生源や入力ルールを確認しながら処理方針を策定することで、価値のあるデータの意図しない消失を防ぐことができます。
やり方②:表記揺れの解消とフォーマット標準化
社内システムごとにデータの入力形式がバラバラな状態では、正確なデータ統合や高度な分析は実現できません。データの真の価値を引き出し、AIの予測精度を高めるには、表記揺れを解消してフォーマットを全社で標準化することが不可欠です。
たとえば、同一の顧客企業であっても、入力元によって以下のように表記が分かれるケースは多々あります。
| システム | 企業名表記 | 電話番号表記 |
|---|---|---|
| 営業支援システム (SFA) | 株式会社A | 03-1234-5678 |
| マーケティングツール (MA) | (株)A | 0312345678 |
| 請求管理システム | カブシキガイシャA | 03(1234)5678 |
このような表記揺れを放置したままシステム連携を実行すると、顧客ごとの正確な売上集計や行動履歴のトラッキングができません。結果として、AIに顧客の購買傾向を学習させようとしても、分散したデータが致命的なノイズとなり予測精度が著しく低下します。
適切なフォーマット設計を行う際は、まず自社にとっての「正しいデータフォーマット(マスターデータ)」を定義することから始めます。全角・半角の統一(例:英数字は半角、カタカナは全角)、大文字・小文字のルール化、日付フォーマット(YYYY/MM/DD)の統一といった標準化作業を行い、ゴールとなる形式を明確にします。
実際の業務においてデータを整備する際、住所などの「連絡先データの正規化基準」を設けることも重要です。「東京都港区芝公園4-2-8」と「東京都港区芝公園四丁目2番8号」の違いを吸収するため、国土交通省や総務省が提供する位置参照情報などを外部マスターとして採用し、どのレベルまで表記を統一するかをプロジェクトの初期段階で合意しておく必要があります。
やり方③:名寄せによる重複データの統合
フォーマットの標準化と並行して行うべきなのが、重複データを統合する「名寄せ」です。顧客データベース内に類似した企業名が複数存在する場合、単に名前が似ているだけで統合してしまうと、グループ会社や別部門のデータを誤って混同するリスクがあります。
たとえば、以下のようなデータ群があったとします。
| 顧客ID | 企業名 | 所在地 | 電話番号 | 判定 |
|---|---|---|---|---|
| C001 | DXナビソリューションズ | 東京都港区 | 03-1111-2222 | 統合元 |
| C002 | DXナビソリューション | 東京都港区 | 03-1111-2222 | C001と同一(名寄せ対象) |
| C003 | DXナビソリューションズ 関西支社 | 大阪府大阪市 | 06-3333-4444 | 別拠点として維持 |
「C001」と「C002」は名称の揺れであり統合すべきですが、「C003」は関西支社という別拠点であるため、安易にC001に統合すると、関西エリアの営業履歴が東京本社に紐づいてしまい、正確な分析ができなくなります。
企業名だけでなく、国税庁が指定する法人番号や電話番号の完全一致など、複数のキーを組み合わせて同一性を判定する厳格なルールを設けることが求められます。担当者の感覚に頼らない仕組みを作り、客観的な基準に基づいてデータを統合することで、精度の高い顧客データベースを構築できます。
名寄せ作業は手作業で行うと膨大な工数がかかるため、後述するツールを活用した自動化が不可欠です。データを統合することで、マーケティング施策の重複配信(同じ企業に何度も同じDMを送ってしまう等のミス)を防ぎ、顧客体験の向上にも寄与します。
やり方④:エクセルからの脱却とツールによる自動化
エクセルのVLOOKUP関数やIF関数、マクロを用いた手作業のデータ処理は、数百〜数千件程度の小規模なデータセットに対しては機能します。しかし、データ量が数万件、数十万件と増加した際には処理が重くなり、必ず破綻します。また、特定の担当者しか複雑な置換ルールを把握していない状態は、担当者の異動によってクレンジング業務そのものが停止してしまう「属人化」のリスクを孕んでいます。
属人化と工数増大の課題を根本から解決するためには、専用のETL(Extract, Transform, Load)ツールやAIを活用したプロセスの自動化が不可欠です。たとえば、「AWS Glue」や「Talend」などのデータ統合ツールを導入すれば、複数システムからデータを抽出する際のフォーマット変換を自動化し、手作業を大幅に削減できます。
さらに近年では、自然言語処理技術を用いたAI搭載のデータクレンジングツールも多数登場しています。従来の単純なルールベース処理では対応が難しかった「文脈を読み取った上での表記揺れの吸収」や「別名義だが同一企業であることの高精度な名寄せ」も、AIを活用することで自動化が可能です。
手作業の限界を早期に認識し、これらのツールによる自動処理を前提とした運用フローを構築することが重要です。これにより、現場に負担をかけずにデータの品質を維持し続けることができます。自社に最適なツールの選び方については、【2026年版】ETLツール徹底比較!自社に最適な製品を選ぶための5つの基準 を参考に、システム構成やデータ量に合った製品を検討してみてください。
やり方⑤:属人化を防ぐ継続的な運用体制の構築
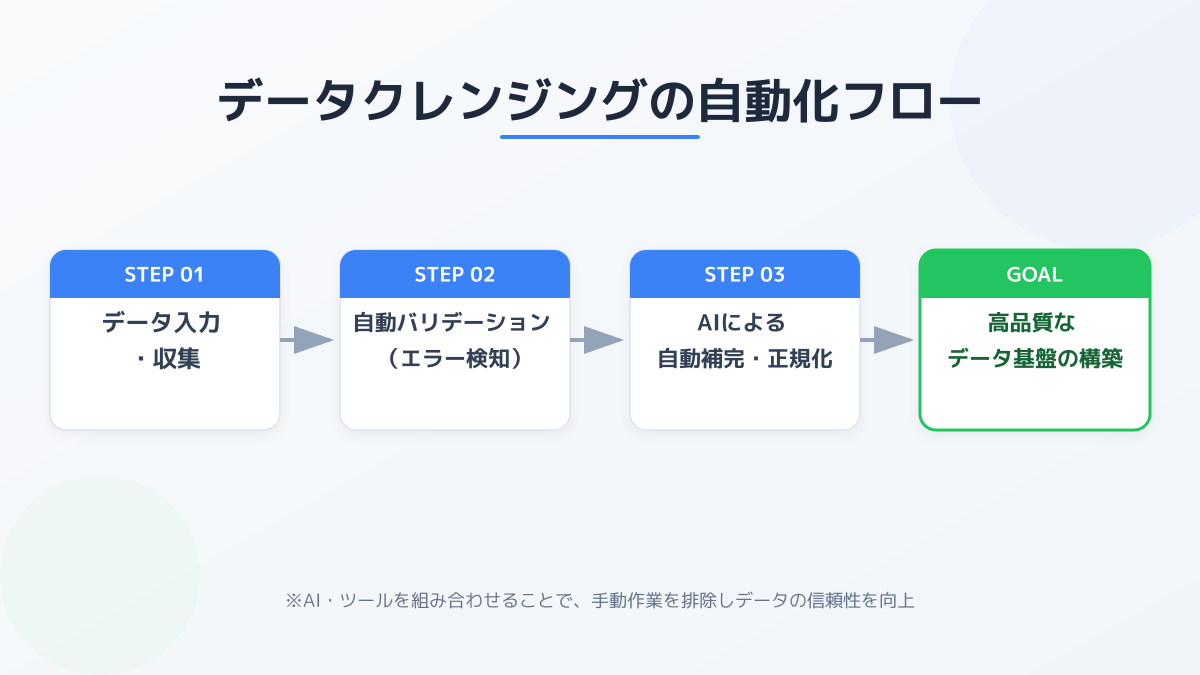
データ活用において見落とされがちなのが、継続的な品質管理と運用体制の構築です。一度データをきれいに整えたとしても、日々の業務を通じて新たなデータが絶えず入力されるため、時間の経過とともに再びノイズや欠損が発生します。
継続的なデータ品質管理を成功させるためには、実行のタイミングや基準を明確に定める必要があります。具体的には、システムへのデータ入力時点でエラーとしてはじく「入力時のバリデーション」、スケジュールに沿って重複や表記ゆれを自動検知する「定期的なバッチ処理」、エラー率が閾値を超えた場合にアラートを発報する「異常値のモニタリング」などを導入します。
現場の業務プロセスにデータクレンジングを定着させる際、最も注意すべきは属人化の排除です。特定の担当者だけが修正ルールや手順を把握している状態を防ぐため、修正ルールを明文化し、社内で共有することが不可欠です。
クレンジングはあくまで発生したエラーを修正する工程であり、根本的な解決には入力段階でのデータ品質向上(データガバナンス)が欠かせません。入力フォームの制限や、現場担当者への入力ルールの周知を並行して進める必要があります。また、処理の過程で重要な情報が意図せず失われないよう、必ず変更履歴(ログ)を保持し、いつでも元の状態にロールバックできる環境を整えておくことも重要です。
よくある質問
データクレンジングとデータクリーニングの違いは何ですか?
データクレンジングとデータクリーニングは、基本的に同じ意味で使われます。どちらもデータのノイズや重複、欠損を取り除き、データの品質を高めるプロセスを指します。企業やツールによって呼び方が異なる場合がありますが、目的は同一です。
エクセルでデータクレンジングを行う際の限界はどこですか?
エクセルを用いた手作業のデータ処理は、データ量が数千件程度であれば手軽に実行できます。しかし、数万件以上の大規模データになると処理速度が著しく低下し、マクロの属人化やヒューマンエラーのリスクが高まります。大規模なデータ処理や高度な名寄せには、専用ツールの導入を推奨します。
データクレンジングを自動化するにはどうすればよいですか?
自動化を実現するためには、まず自社のデータ品質基準と処理ルールを明確に定義します。その上で、ETLツールやAIを搭載したデータクレンジングツールを導入し、データ入力時のバリデーションや定期的なバッチ処理をシステムに組み込むことで、手作業を最小限に抑えることができます。【2026年版】デジタル化とは簡単に言うと?DX化との違いやデメリット・推進手順を完全ガイド も参考に、社内のデジタル化を推進してください。
まとめ
本記事では、AIの精度を劇的に高め、データドリブン経営を推進するためのデータクレンジングの5つの具体的なやり方を解説しました。目的と対象範囲の明確化から始まり、欠損値・異常値の適切な処理、表記揺れの解消とフォーマット標準化、名寄せによる統合、エクセルからの脱却とツールによる自動化、そして継続的な運用体制の構築まで、多岐にわたる側面からその重要性を強調しました。
これらのプロセスを体系的に実行し、組織全体でデータ品質を維持する仕組みを構築することで、データの真の価値を引き出し、ビジネス成果へと直結させることが可能になります。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事

データクレンジングとは?AI精度を高めるツール選び3つの極意【2026年版】
手作業では限界がある膨大なデータ処理を自動化し、品質を担保するデータクレンジングツール。本記事では、自社の課題に合わせた最適なツールの選び方や比較のポイントを解説し、導入実績の豊富な無料・有料のおすすめツールを厳選して紹介します。
プロセスマイニングとは?DX推進を成功に導く8つのポイント【2026年版】
企業の業務プロセス改善において、担当者の感覚に頼らないデータドリブンなアプローチとして注目される「プロセスマイニング」。システム上のログデータを活用して真のボトルネックを特定する仕組みや、DX推進における具体的な導入メリットを解説します。
データレイクハウスとは?DWH・データレイクとの違いと導入6ポイント【2026年版】
データウェアハウス(DWH)のパフォーマンスとデータレイクの柔軟性を兼ね備えた新しいデータ管理基盤「データレイクハウス」。AIや機械学習の進展に伴いなぜこのアーキテクチャが求められているのか、そのメリットと従来型との決定的な違いを解説します。

SaaSにおけるLTVの計算方法を8つのポイントで解説!CAC比率で健全な成長へ
SaaSビジネスの健全性を測る上で欠かせない「LTV/CACレシオ(比率)」。LTVの正確な計算式から、顧客獲得単価(CAC)との理想的なバランス「3倍の法則」について、事業計画で失敗しないためのLTVの計算方法を解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。
LLM RAGとは?情報漏洩を防ぐ企業向けローカル環境構築5ステップ【2026年版】
企業がLLMを安全に活用するために欠かせない「RAG(検索拡張生成)」と「ローカルLLM」。社内の機密データを外部に漏らさずに独自のAIを構築する仕組みと、ビジネス実装に向けた具体的なステップを解説します。