ローカルLLM・オンプレミス生成AI導入ガイド|情報漏洩を防ぐ5ステップ【2026年版】
機密情報を扱う企業向けに、情報漏洩リスクを防ぐ「オンプレミス環境での生成AI導入」を徹底解説。クラウドとの違いや構築メリット、具体的な5つの手順、最新事例まで網羅的に紹介します。

オンプレミス環境で生成AIを導入する最大のメリットは、機密情報の流出リスクを極小化し、強固なセキュリティとデータ主権を確立できる点です。金融や医療、製造業など、外部ネットワークにデータを送信できない企業において、自社専用のAI基盤構築が急増しています。本記事では、オンプレミス環境での生成AIの具体的な導入手順と、構築するメリット、最新の成功事例、そして失敗しないための運用戦略を徹底解説します。
オンプレミス環境でAIを構築するメリットと背景
近年、クラウドサービスへの全面的な移行が企業のIT戦略における主流となっていましたが、ここに来て自社内にサーバーやネットワーク機器を設置・運用するオンプレミス環境が再び注目を集めています。
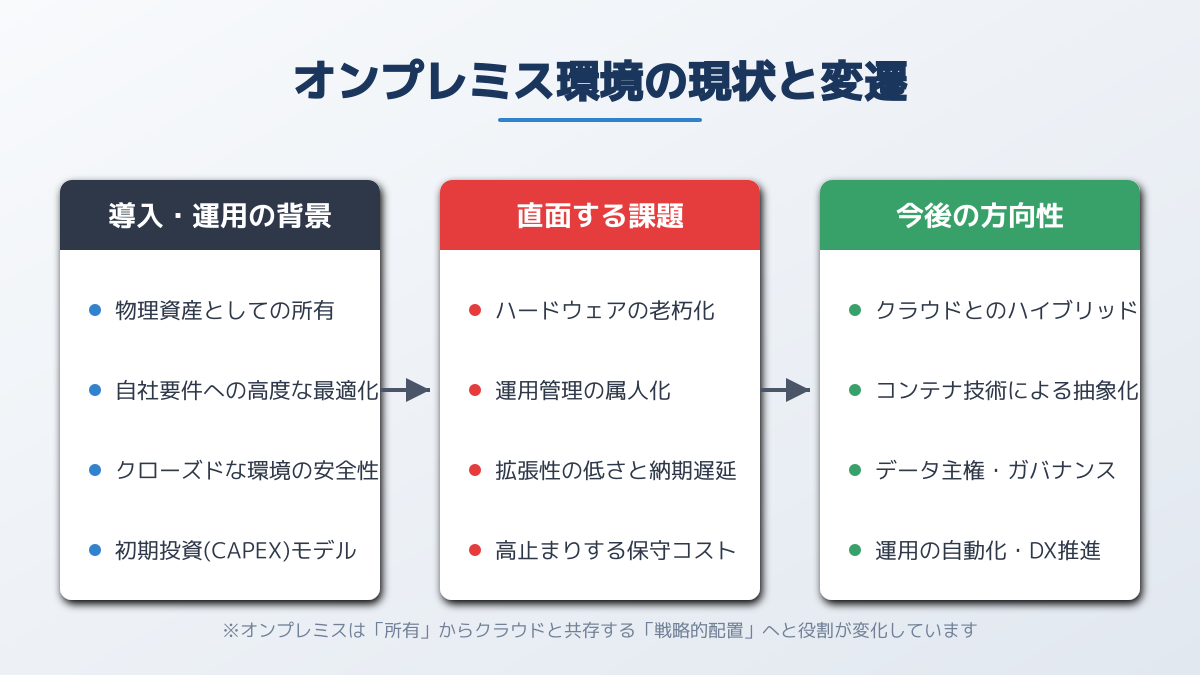
この動きの背景には、クラウド運用における課題の顕在化と、最新のAIテクノロジーを安全かつコスト効率よく活用するためのインフラ要件の変化があります。
クラウド全盛期になぜオンプレミスが再評価されているのか
クラウドサービスは初期費用を抑え、迅速にシステムを構築できる点で多くの企業に採用され、DX(デジタルトランスフォーメーション)推進の原動力となってきました。しかし、運用規模が拡大し、社内のあらゆるシステムがクラウドに依存するようになると、従量課金によるランニングコストの想定外の膨張やベンダーロックインのリスクが浮き彫りになっています。
さらに、昨今のビジネス変革において中核となる人工知能の活用が、オンプレミス回帰の流れを加速させています。企業が独自の競争力を生み出すためには、自社が保有する機密データや顧客情報をAIに学習させる必要があります。しかし、パブリッククラウド上のサービスや外部APIを経由して機密データを処理することに対し、情報漏洩やデータ二次利用の懸念を抱く経営層は少なくありません。
また、技術的な進化も後押ししています。NVIDIAの最新GPUの登場や、Llama 4、DeepSeekといった高性能なオープンソースモデルの台頭、Ollamaなどのツールによるローカル推論の容易化により、自社環境で高度なAIを稼働させるハードルは劇的に下がりました。そのため、厳格なデータ保護要件を満たしつつ高度なデータ処理を行う手段として、自社専用となるオンプレミス環境での生成AIの構築や、機密性の高い業務プロセスに特化したオンプレミス型のAI導入を検討する企業が急増しています。
オンプレミス環境構築の3つのメリットと判断ポイント
オンプレミス環境を構築すべきか、クラウドを継続利用すべきかを判断するには、自社のビジネスモデルや中長期的なIT戦略に照らし合わせて複数の観点から評価し、メリットを整理する必要があります。全体的な方針を定める際には、IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイント を活用して自社の方向性を明確にし、関係者間で合意形成を図ることが有効です。
1つ目のメリットであり判断ポイントは、 コスト構造の長期的最適化 です。オンプレミスはサーバー機器の購入やデータセンターの確保など、多額の初期投資(CapEx)を伴います。しかし、稼働年数が長く、トラフィックやデータ処理量が一定以上の規模で安定しているシステムであれば、3〜5年単位の総所有コスト(TCO)はクラウドの継続的な運用費(OpEx)よりも低く抑えられることが一般的です。
2つ目は、 最高レベルのセキュリティ要件とデータガバナンスの確保 です。金融機関、医療機関、あるいは高度な技術情報を持つ製造業など、コンプライアンス規制を受ける企業にとって、データを物理的に自社管理下に置けるオンプレミス環境は強力な選択肢です。外部ネットワークから完全に遮断された閉域網を構築し、サイバー攻撃のリスクを極小化するとともに、法的なガバナンスを完全に自社で統制することが可能です。
3つ目は、 インフラ管理の完全な統制とカスタマイズ性 です。オンプレミス環境は高い自由度と強固なセキュリティを提供する一方で、ハードウェアの保守や物理的な環境整備を自社で完結させる必要があります。自社の用途に合わせた独自のAIモデルや特定業務に特化したチューニングを、他システムの影響を受けずに構築できる点は、クラウドにはない大きなメリットとなります。
オンプレミス環境で生成AIを導入する手順
生成AIなどの高度な技術を自社専用のインフラで稼働させるシステムの構築は、強固なセキュリティや柔軟なカスタマイズ性を実現する上で非常に有効な選択肢です。しかし、クラウドサービスと比較して初期投資が大きく、設計や運用の難易度も高いため、場当たり的な導入はプロジェクトの頓挫を招きかねません。

ここでは、自社専用のインフラ構築を進めるための具体的な手順と、各フェーズにおける具体的な構成例やツール選定の判断ポイントを解説します。
ステップ1:導入目的の明確化と要件定義
最初のステップは、システムを自社内に構築する目的を明確にし、要件定義を行うことです。特にオンプレミス環境での生成AI導入を検討する場合、「なぜクラウドではなく自社インフラでなければならないのか」を論理的に説明できる必要があります。
判断ポイントとなるのは、取り扱うデータの機密性とコンプライアンス要件です。顧客の個人情報、未公開の財務データ、製造業における独自の設計図面など、外部ネットワークに一切送信できないデータを用いてAIを学習・活用させる場合、自社内でのインフラ構築が必須となります。この段階で、法務部門やセキュリティ部門を交えて要件をすり合わせます。クラウドサービスの利用コストと自社構築の初期費用・運用保守費用を比較し、中長期的な投資対効果(ROI)を厳格に評価してください。たとえば、クラウドのAPI利用料やデータ転送費用が継続的に月額100万円発生するケースでは、初期費用に3,000万円を投じて自社インフラを構築しても、数年でコストが逆転する可能性があります。
ステップ2:ハードウェアの選定と物理環境の整備
目的と要件が固まったら、次にサーバーやネットワーク機器といったハードウェアの選定に進みます。このフェーズでの最大の判断ポイントは、将来の拡張性を見据えた適切なサイジング(規模の見積もり)と、物理的なファシリティの確保です。
高度な処理を要求されるオンプレミス型のAIを快適に動作させるためには、高性能な構成が不可欠です。具体的な構成例としては、エンタープライズ向けの「NVIDIA DGX」シリーズや、計算処理に特化した「NVIDIA H100 Tensor コア GPU」、あるいは「NVIDIA A100」を搭載したAI専用サーバーの導入が一般的です。また、これらを支える大容量のメモリ、および高速なデータ読み書きが可能なオールフラッシュストレージ(NVMe SSDなど)を組み合わせます。導入初期の業務要件を満たすだけでなく、将来的なデータ量の増加や、より大規模なAIモデルへの移行に耐えうる拡張性を持たせた構成にすることが重要です。
また、高性能なサーバー群は膨大な電力を消費し、多量の熱を発生させます。そのため、データセンターやサーバールームの電力供給能力や冷却設備が十分であるかを確認することも、重要な判断ポイントとなります。
ステップ3:ソフトウェアスタックとセキュリティ設計
ハードウェアの構成が決定したら、AIモデルを稼働させるためのソフトウェアスタックを選定します。近年はMetaの「Llama 4」や「DeepSeek」、あるいは「ELYZA」や「Swallow」といった国産の高性能なオープンソース大規模言語モデル(LLM)が登場しており、これらを自社向けにカスタマイズ(ファインチューニング)して活用するケースが増えています。
実行環境のツール例としては、推論処理を高速化する「vLLM」や「Triton Inference Server」、またローカル環境での推論サーバー構築を容易にする「Ollama」や「LocalAI」などが広く利用されています。さらに、社内ドキュメントとAIを連携させるRAG(検索拡張生成)を構築する場合は、「LangChain」や「LlamaIndex」といったフレームワークと、ベクトルデータベース(MilvusやQdrantなど)を組み合わせるのが標準的な構成です。
同時に、自社インフラの最大のメリットであるセキュリティ設計を緻密に行います。外部インターネットから完全に遮断された閉域網(エアギャップ環境)を構築するのか、特定の社内システムと安全に連携させるためのAPIゲートウェイを設けるのかを決定します。アクセス権限の厳格な管理や、すべての操作ログを監視・記録する体制を設計に組み込むことで、内部不正やサイバー攻撃への耐性を高めます。
ステップ4:テスト環境での検証とパイロット運用
本番環境へ一斉に展開する前に、小規模なテスト環境を構築して実証実験(PoC)を実施します。ここでは、AIの応答速度、生成される回答の精度、そしてシステム全体の安定性を検証します。
実際の業務を想定したテストデータを入力し、期待するパフォーマンスが発揮できるかを確認します。特にAIモデルが事実と異なる情報を生成するハルシネーションのリスクを評価し、業務に支障が出ないレベルに制御できるかを検証します。また、一部の現場担当者にパイロット版として試用してもらい、UIの使いやすさや業務フローとの適合性についてフィードバックを収集します。この段階で発見された課題を解消するためのチューニングを行い、本番稼働に向けた完成度を高めていきます。
ステップ5:現場への展開と運用体制の構築
テスト運用で十分な成果が確認できたら、いよいよ全社または対象部門への本格展開に移行します。自社インフラは構築して終わりではなく、継続的なメンテナンスが求められます。
ハードウェアの物理的な保守管理、ソフトウェアの定期的なアップデート、そしてAIモデルの精度を維持・向上させるための再学習(ファインチューニング)など、運用業務は多岐にわたります。そのため、システム部門と業務部門が密に連携できる運用体制の構築が不可欠です。
トラブル発生時のエスカレーションフローや、日常的なモニタリング手順をマニュアル化します。さらに、AIを正しく活用するためのプロンプトエンジニアリングのガイドラインを策定するなど、社内人材の育成を並行して進めてください。
また、構築した高度なインフラを既存業務の効率化にとどめず、新たなビジネスモデルの創出に活用することも重要です。もし、テクノロジーを起点とした新規事業のアイデア出しや立ち上げにリソース不足や難しさを感じる場合は、【2026年版】新規事業のアイデアが思いつかない?コンサル活用で立ち上げの「きつい」を乗り越える3ステップと自走化手順 を参考に、専門家の知見を取り入れながらプロジェクトの自走化を目指すアプローチも検討してください。
オンプレミス環境での生成AI導入成功事例
自社専用のインフラで生成AIを稼働させることで、劇的な業務効率化を実現している企業の事例を紹介します。
医療機関における退院サマリの自動作成
ある総合病院では、オンプレミス環境に専用の生成AIサーバーを導入し、電子カルテや読影レポート、院内規約と連携するRAG(Retrieval-Augmented Generation)機能を活用した対話型支援システムを構築しました。これにより、医師の負担となっていた退院サマリの自動作成が可能となり、作成にかかる稼働時間を52.8%削減することに成功しています。患者の個人情報という極めて機密性の高いデータを扱うため、外部ネットワークに接続しないオンプレミス環境が必須要件でした。
金融機関における書類作成の効率化
大手クレジットカード会社では、債権管理業務における訴訟対応のドラフト作成(準備書面や証拠説明書など)を支援するオンプレミス型生成AIシステムを開発しました。過去の係争案件データを安全な社内環境で学習させることで、案件の約8〜9割において高精度な書類作成が可能となり、法務部門の大幅な業務効率化を実現しています。
オンプレミス環境のAI運用で失敗しないポイント
生成AIを自社専用のインフラで稼働させる試みは、高いセキュリティとカスタマイズ性を得られる反面、構築や運用におけるハードルが非常に高くなります。初期設定の甘さや運用体制の不備が、プロジェクト全体の頓挫を招くケースも少なくありません。

本セクションでは、自社インフラへのAI導入を成功に導くための基本事項から、導入可否の判断基準、そして現場での運用における具体的な注意点までを解説します。
失敗を防ぐための基本事項と事前準備
自社専用のインフラを構築する際、最も多い失敗の原因は、ハードウェアリソースの過小評価とネットワーク設計の甘さです。特にAIモデルを稼働させる場合、従来の業務システムとは異なるアプローチが求められます。
ハードウェアリソースの厳密な見積もり オンプレミス環境で生成AIを稼働させるためには、高性能なGPU(画像処理半導体)を搭載したサーバーが不可欠です。テキスト生成や画像生成の基盤となる大規模言語モデル(LLM)は、推論処理だけでも膨大な計算資源を消費します。
導入前の検証(PoC)段階で、自社が想定する同時接続数や処理速度の要件を満たすために必要なGPUの枚数とメモリ容量を正確に算出する必要があります。GPUサーバーは発熱量が大きく、消費電力も高いため、データセンターやサーバルームの電源容量および空調設備の増強が必要になるケースが一般的です。ハードウェアの調達から設置環境の整備まで、数ヶ月から半年以上のリードタイムを見込む必要があります。
セキュリティ要件とネットワーク設計の最適化 機密データを扱うために外部ネットワークから遮断された環境を構築する場合でも、内部のネットワーク設計をおろそかにしてはいけません。学習データやプロンプトに含まれる機密情報が社内の権限のないユーザーに漏洩しないよう、厳格なアクセス制御(IAM)と通信の暗号化を実装します。
また、AIモデルのアップデートやパッチ適用のために、一時的に外部ネットワークと接続する際の安全な経路(プロキシサーバーやVPN)の確保も、初期段階で設計に組み込む必要があります。
クラウドかオンプレミス環境かの判断ポイント
自社の要件に対して、本当に物理サーバーを自社で所有・管理する形態が最適なのか、導入前に冷静に判断することが重要です。以下の3つの軸で評価を行います。
データガバナンスと機密性のレベル オンプレミス型のAIを選択する最大の理由は、データの完全なコントロールです。製造業の未公開の設計データ、医療機関の電子カルテ情報、金融機関の顧客取引データなど、外部のクラウドサーバーに送信すること自体がコンプライアンス違反となる情報を扱う場合、自社インフラでの構築が必須となります。
逆に、公開済みの情報や一般的な業務マニュアルの検索用途であれば、クラウド型の生成AIサービスを利用する方が、導入スピードとコストの面で圧倒的に有利です。
コスト構造の比較と投資対効果 オンプレミス環境は、サーバー機器の購入、ネットワーク機器の調達、ソフトウェアライセンスの取得など、初期投資(CAPEX)が数千万円規模に膨らむことがあります。さらに、ハードウェアの保守費用、電気代、データセンターのラック費用などのランニングコスト(OPEX)も継続して発生します。
クラウドサービスは利用した分だけ費用が発生する従量課金制が基本です。3〜5年間の総所有コスト(TCO)を算出し、自社インフラを所有することで得られるセキュリティ上のメリットが、そのコスト差額に見合う価値を提供するかを定量的に評価します。ハードウェアの減価償却費とクラウドの利用予測を比較し、損益分岐点がどこにあるかを事前にシミュレーションしておくことが重要です。
スケーラビリティと柔軟性の必要性 AIの利用規模が将来的にどの程度拡大するか予測が難しい場合、物理サーバーの増設には時間とコストがかかります。クラウドであれば、数クリックでリソースを拡張・縮小できます。
初期段階ではクラウドの閉域網接続(プライベートクラウド)を利用してスモールスタートを切り、利用規模と要件が固まった段階で自社インフラへ移行するというハイブリッドなアプローチも、リスクを抑える有効な選択肢です。
現場で運用する際の注意点と体制構築
ハードウェアの構築が完了しても、現場での運用体制が整っていなければ、AIシステムはすぐに陳腐化し、投資対効果を得られません。運用フェーズにおける具体的な注意点を整理します。
専門人材の確保と役割分担 AIシステムの運用には、インフラエンジニアとAIエンジニアの双方が必要です。インフラエンジニアは、GPUサーバーの死活監視、ネットワークの帯域管理、ハードウェアの故障対応を担います。一方、AIエンジニアは、モデルの精度モニタリング、追加学習(ファインチューニング)の実施、プロンプトの最適化を担当します。
社内にこれらの専門スキルを持つ人材が不足している場合、外部のベンダーやコンサルティング企業の支援を仰ぐことになります。しかし、完全に丸投げするのではなく、自社の業務要件を理解し、ベンダーをコントロールできる社内のプロジェクトマネージャーを必ず配置します。
保守・監視体制の確立と障害対応 物理サーバーを運用する以上、ハードウェアの故障は避けられません。GPUやメモリの障害が発生した場合に備え、冗長化構成(HAクラスタ)を組むか、代替機を速やかに手配できる保守契約をハードウェアベンダーと締結しておきます。
また、AIモデル特有の監視項目として、出力結果の品質低下(ハルシネーションの増加など)や、処理遅延の発生を検知する仕組みを導入します。異常を検知した際のエスカレーションフローを事前に定義し、現場の業務への影響を最小限に抑える手順を確立します。
リソースの最適化と継続的なアップデート AI技術の進化は非常に早く、数ヶ月単位でより軽量かつ高性能な新しいオープンソースモデルが登場します。自社インフラ上で稼働させるモデルを定期的に評価し、必要に応じて最新のモデルへ入れ替える運用プロセスを構築します。
同時に、GPUリソースの利用状況を可視化し、特定の時間帯に処理が集中してパフォーマンスが低下していないか、逆にリソースが余剰になっていないかを分析します。バッチ処理のスケジュールを調整するなど、限られたハードウェアリソースを最大限に活用する工夫が、長期的な運用成功の鍵となります。
まとめ
本記事では、生成AIを オンプレミス環境 で構築する際のメリット・デメリット、具体的な導入手順、そして成功に導くためのポイントを詳しく解説しました。
オンプレミスでの生成AI導入は、高いセキュリティとカスタマイズ性を実現できる一方で、初期投資や運用負荷が大きいという側面があります。しかし、適切な計画と戦略的なアプローチによって、これらの課題は克服可能です。
重要なポイントは以下の通りです。
- データ主権やセキュリティ要件からオンプレミスが再評価されていること
- 導入には、要件定義から運用・保守まで、計画的な手順を踏むこと
- 失敗しないためには、明確な目的設定、専門人材の確保、継続的な運用体制の構築が鍵となること
自社のビジネス要件とリスク許容度を慎重に評価し、最適な生成AIインフラ戦略を構築することで、DX推進を加速させ、競争優位性を確立できるでしょう。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事
LLM RAGとは?情報漏洩を防ぐ企業向けローカル環境構築5ステップ【2026年版】
企業がLLMを安全に活用するために欠かせない「RAG(検索拡張生成)」と「ローカルLLM」。社内の機密データを外部に漏らさずに独自のAIを構築する仕組みと、ビジネス実装に向けた具体的なステップを解説します。
システム運用とは?保守との違いと属人化を防ぐ6つのポイント【2026年版】
企業のITインフラを支えるシステム運用とシステム保守。似て非なる両者の業務内容の違いを明確にし、日々の運用管理で発生しやすい属人化やヒューマンエラーを防ぐための体制構築、自動化のポイントを解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。

BPOとは?アウトソーシングとの違いと導入7ステップ・成功事例【2026年版】
業務の属人化や人手不足を解消し、コア業務に集中できる体制を作りたい方へ。BPO(ビジネス・プロセス・アウトソーシング)の基本から、一般的なアウトソーシングとの違い、失敗しない導入手順を徹底解説します。自社のDX推進と業務効率化を実現するロードマップを手に入れましょう。

LLMo対策とは?LLMOps構築と運用を成功させる7つのポイント
開発したLLMをビジネスの現場で継続的かつ安定して運用するためのフレームワーク「LLMOps」。モデルの評価やプロンプト管理など、生成AIのライフサイクルを自動化・効率化する最新トレンドと構築手順を解説します。

Cドライブ容量不足の原因を特定!情シスが実践するPC管理とDX基盤の最適化
「不要なファイルを削除したのにCドライブの空き容量が増えない」という原因不明のトラブルに対処する情シス・IT部門向けのガイド。システムの一時ファイルなど見落としがちな容量圧迫要因を特定する手順に加え、クラウドストレージの活用やデータガバナンスの強化といったDX推進に向けた根本的な解決策を解説します。