AWSのETLでデータ統合を加速!構築と運用を成功に導く6つの秘訣
クラウドネイティブなデータ分析基盤を構築する上で欠かせないAWSでのETL処理。本記事では、フルマネージド型のデータ統合サービス「AWS Glue」を中心としたアーキテクチャの基本設計から、効率的かつ安全にETL処理を実装するためのベストプラクティスを解説します。

データ活用が企業の競争力を左右する現代において、散在するデータを効率的に統合するため、AWSを活用したETL環境を構築することはDX推進の鍵です。AWS環境でETL処理を成功させるには、最適なサービス選定から運用まで、具体的なステップと注意点を押さえることが不可欠です。
本記事では、AWS Glueをはじめとするサービスを活用し、スケーラブルで堅牢なデータ連携基盤を構築・運用するための6つの重要ポイントを解説します。これにより、データドリブンな意思決定を加速し、ビジネス変革を実現するための実践的なノウハウが得られます。
最適なサービスの選定
データ活用が企業の競争力を左右する中、クラウド上での迅速なデータ統合は不可欠です。そもそも「ETLとは何か?」そして「AWS環境でETL処理をどう実現するのか?」という疑問を持つ方も多いでしょう。AWSにおけるETL(Extract, Transform, Load)とは、社内外に散在するデータを抽出し、分析しやすい形に変換した上で、データウェアハウスなどへロードする一連のデータ連携プロセスを指します。
AWSを利用したETL処理を構築する上で最初のポイントとなるのは、自社のデータ量と処理頻度に応じた最適なサービスの選定です。AWSにはフルマネージド型のデータ統合サービスであるAWS Glueをはじめ、大規模分散処理に向いたAmazon EMRなど、多様な選択肢が存在します。バッチ処理かリアルタイム処理か、または開発チームのスキルセットがコードベースかノーコードかといった要件が、サービス選定の重要な判断ポイントとなります。
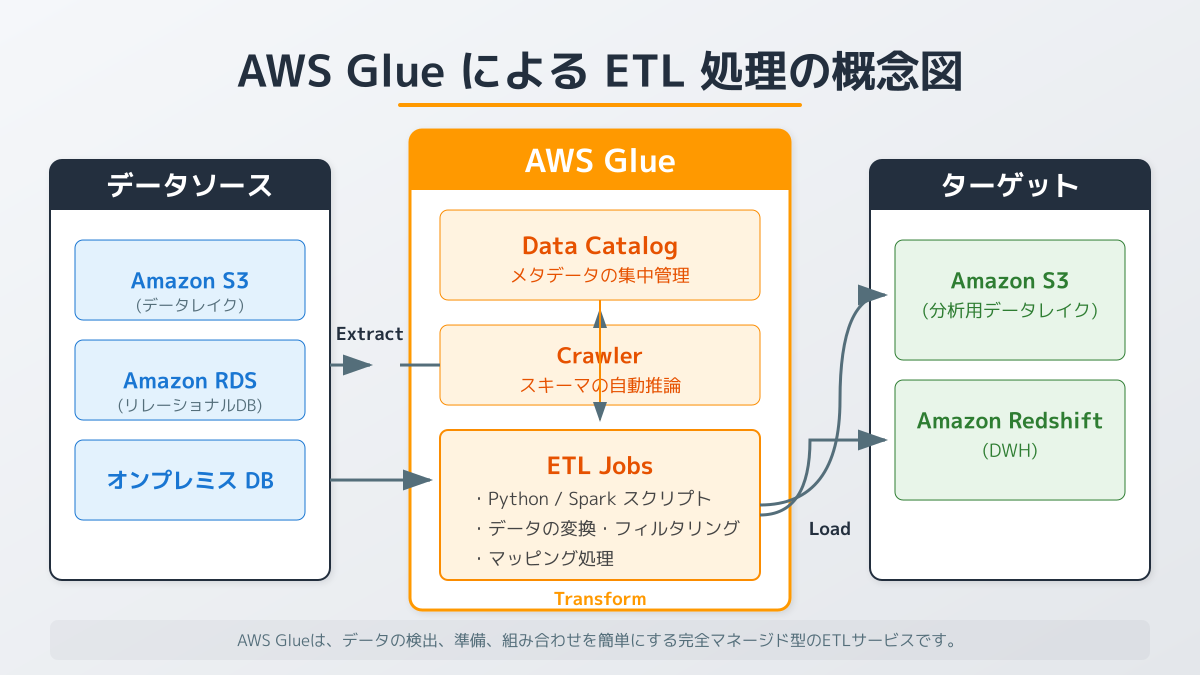
実際に現場で運用を開始する際の注意点として、厳密なコスト管理とエラーハンドリングの設計が挙げられます。AWS Glueのようなサーバーレス環境はインフラ管理の手間を大幅に削減しますが、非効率なデータ処理が続くと想定以上のコストが発生するリスクがあります。そのため、データのパーティショニングや適切なリソースの割り当てを行い、処理時間を最適化することが求められます。
これらの基本事項と注意点を押さえ、ビジネス目標に直結するデータ連携基盤を設計することがプロジェクト成功の鍵です。全体的なシステム構想を練る際は、IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイントも参考にしながら、自社のデータ戦略を経営課題の中で明確に位置づけることをおすすめします。
スケーラビリティとコストの最適化
AWS環境におけるデータ基盤構築において、スケーラビリティとコスト最適化の両立は欠かせない基本事項です。企業が扱うデータ量は日々増加しており、将来的な拡張を見据えたアーキテクチャ設計が求められます。
構成判断の具体化と現場運用の注意点
AWSでのETL環境構築では、フルマネージドサービスであるAWS Glueを活用したサーバーレス構成にするか、Amazon EC2などを利用して独自に構築するかの判断が重要です。運用工数の削減と柔軟なリソース拡張を優先する場合、AWS Glueを中心とした構成が推奨されます。
一方で、現場で運用する際にはコスト管理に注意が必要です。AWSのETL処理においてデータ量に応じた従量課金制はメリットですが、無駄な処理が走ると想定外の費用が膨らむリスクがあります。そのため、処理スクリプトのチューニング(例:PySparkを用いた処理におけるデータスキューの解消)や、AWS GlueのG.1X、G.2Xといったワーカータイプの適切なサイジング、不要なジョブの定期的な見直しが必須です。
また、堅牢なデータ基盤の整備は既存業務の効率化にとどまらず、新たなビジネスモデル創出の土台にもなります。データ活用を起点とした新規事業を検討する際、社内のリソースやノウハウ不足に直面した場合は、【2026年版】新規事業のアイデアが思いつかない?コンサル活用で立ち上げの「きつい」を乗り越える3ステップと自走化手順も有効な選択肢となります。
要点を整理すると、AWSでのETL構築は「サーバーレスによる運用負荷の軽減」と「継続的かつ厳密なコスト管理」のバランスを見極めることが成功の鍵です。自社のデータ規模と運用体制に合わせて、最適なサービス選定と運用ルールを策定しましょう。
複数サービスの適材適所な組み合わせ
AWSを利用したデータ連携基盤の構築において、単一のサービスですべてを完結させるのではなく、適材適所で複数のマネージドサービスを組み合わせることが基本となります。データの収集、加工、蓄積といった各フェーズにおいて、自社のビジネス要件に合ったサービスを選択することが、システム全体のパフォーマンス向上とコストの最適化に直結します。
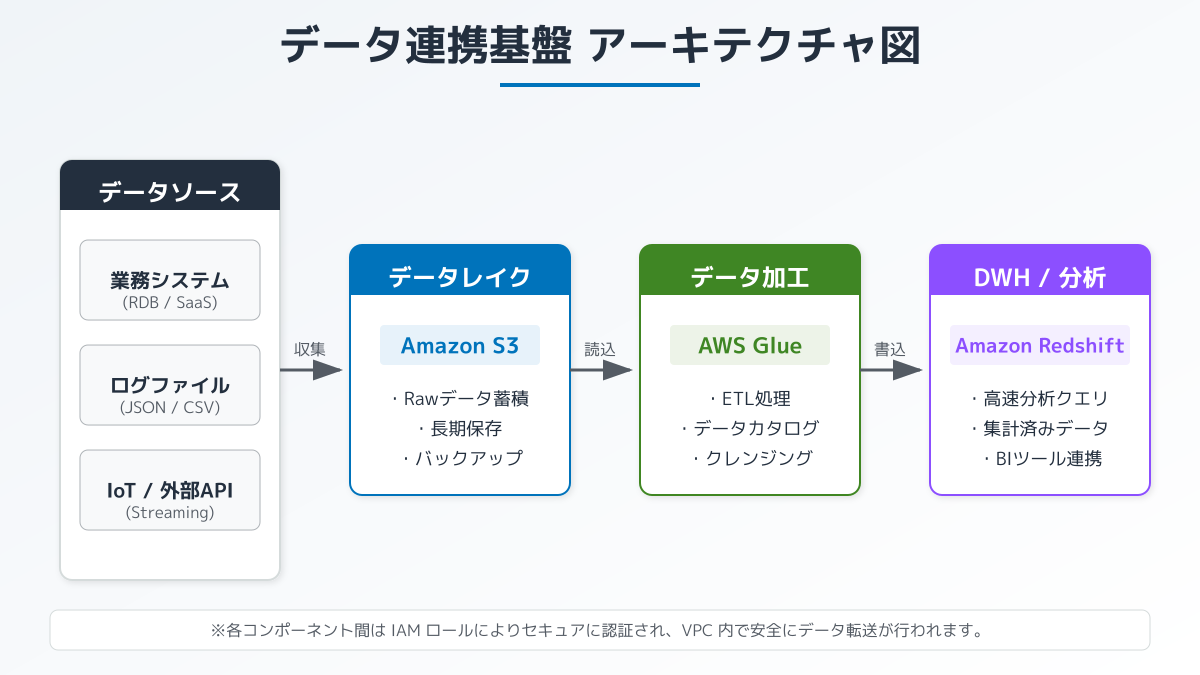
最適なサービスを組み合わせる判断ポイント
データ連携基盤の王道とも言える構成は、データレイクとして大容量ストレージのAmazon S3を採用し、データ変換処理をAWS Glueで実行、そして最終的な分析用データウェアハウスとしてAmazon Redshiftに格納するアーキテクチャです。
ここで重要となる判断ポイントは、扱うデータ量、処理の実行頻度、および求められるリアルタイム性です。日次や週次などのバッチ処理であればAWS Glueが最適ですが、リアルタイムに近いストリーミングデータの処理が必要な場合は、Amazon Kinesisなどの活用を検討する必要があります。自社に最適なAWSのETLアーキテクチャを設計するためには、まずビジネス側が求めるデータの鮮度とボリュームを明確に定義することが不可欠です。
現場で運用する際の注意点
アーキテクチャが決定し、実際に現場で運用を開始すると、データ量の増加に伴う処理時間の遅延や、予期せぬインフラコストの増大といった課題に直面することが少なくありません。
これらのリスクを回避するためには、AWS Glueのワーカー数やDPU(Data Processing Unit)の適切なサイジングを定期的に見直す必要があります。また、Amazon CloudWatchを活用したリソースのモニタリングや、処理失敗時の自動リトライ制御、担当者への迅速なエラー通知の仕組みをあらかじめ組み込んでおくことが重要です。現場でAWSのETL基盤を長期間にわたり安定稼働させるためには、開発段階から運用保守を見据えた堅牢な設計が求められます。
アーキテクチャ設計と運用の要点
ここまでの構成検討と運用における要点を整理します。
- 適材適所のサービス選定: S3、Glue、Redshiftなど、各フェーズの目的に合致したAWSサービスを組み合わせる。
- 要件に基づく構成判断: データ量や処理頻度を基準に、バッチ処理かストリーミング処理かを見極める。
- 運用を見据えた設計: リソースの継続的な最適化やエラー監視の仕組みを導入し、運用負荷を最小限に抑える。
これらの基本事項と注意点をしっかりと押さえることで、データ量の増加やビジネスの変化に柔軟に対応できる、スケーラブルで可用性の高いデータ連携基盤を実現できます。
エラーハンドリングとリトライ設計
データ連携基盤を構築する際、AWSを用いたETLの実践において見落とされがちなのが、運用フェーズを見据えたエラーハンドリングとリトライ設計です。AWS環境でのETL処理では、データソースの一時的な接続エラーや、想定外のデータ形式による不整合など、予期せぬトラブルが日常的に発生する可能性があります。ここでは、システムを安定稼働させるための基本事項と要点を整理します。
運用を見据えた判断ポイントの具体化
AWSのETL処理環境下において、どのタイミングで処理を中断し、どの段階から再実行させるべきかの判断ポイントを具体化しておくことが、データ品質を担保する鍵となります。具体的には以下の要点を押さえる必要があります。
- リトライ回数の上限設定: 無限ループによる無駄なコスト発生を防ぐため、AWS Glueのジョブ設定で適切なリトライ回数とタイムアウト時間を明確に定義します。
- エラー通知とワークフロー管理の自動化: Amazon CloudWatchとAmazon SNSを連携させて即時アラートを送信するだけでなく、AWS Step Functionsを活用して複数ジョブのオーケストレーションと、失敗時のフォールバック処理(代替処理)を自動化する仕組みを構築します。
- 部分再実行(冪等性)の設計: 処理全体を最初からやり直すのではなく、失敗した箇所から安全に再開(冪等性を担保)できるよう、処理の途中で中間データをAmazon S3に保存するアーキテクチャを採用します。
これらの要点を整理して設計に組み込むことで、障害発生時のダウンタイムを最小限に抑え、データパイプライン全体の信頼性を飛躍的に高めることができます。
現場で運用する際の注意点
システムを現場で運用する際の最大の注意点は、データ量の増加に伴うパフォーマンスの低下です。ビジネスの成長とともに処理対象のデータが膨張すると、初期設計時のリソースでは処理時間が長期化するケースが頻発します。そのため、定期的に処理パフォーマンスをモニタリングし、AWS GlueのDPU(Data Processing Unit)の割り当てリソースを柔軟に見直すことが不可欠です。
また、セキュリティ観点でのアクセス制御も重要です。開発環境と本番環境でIAM(Identity and Access Management)ロールを厳格に分離し、最小権限の原則に従って権限を付与することで、意図しないデータの改ざんや情報漏洩のリスクを低減できます。運用フェーズでの安定性を継続的に確保するためには、こうした基本事項を徹底し、現場の運用プロセスに定着させることが求められます。
データ品質の担保とセキュリティ対策
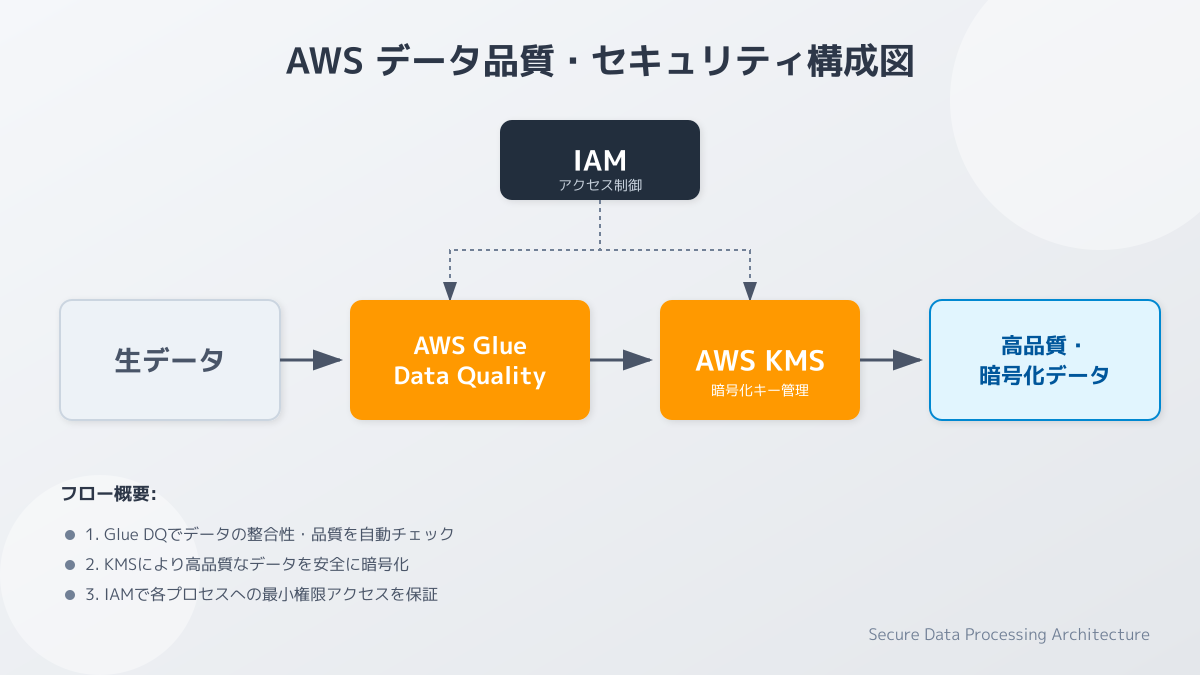
AWSを活用したデータ連携基盤を構築する上で、5つ目の重要なポイントとなるのが「データ品質の担保とセキュリティ対策」です。
セキュリティとデータ品質管理の基本事項
AWS環境でETLを実装する際、単にデータを移動・変換するだけでなく、その過程における安全確保と正確性の維持が強く求められます。セキュリティ面では、AWS Identity and Access Management (IAM) を用いた最小権限の原則に基づくアクセス制御や、AWS Key Management Service (KMS) を活用したデータの暗号化が基本事項となります。また、データ品質管理においては、AWS Glue Data Qualityなどを利用して、データの異常値や欠損値を自動的に検知する仕組みを組み込むことが重要です。
導入時の判断ポイント
自社の要件に合わせて、どの程度の対策を講じるべきかを具体化する必要があります。主な判断ポイントとなるのは、扱うデータの機密性レベルと、ビジネス側が求めるデータの鮮度・正確性のバランスです。たとえば、個人情報や機密データを含む場合は、抽出(Extract)の直後にマスキング処理を行うフローを設計しなければなりません。一方で、品質チェックを厳密にしすぎると処理時間が大きく増大するため、要件に応じた適切なチェック項目を選定することが不可欠です。
現場で運用する際の注意点
実際に現場で運用を開始した後は、エラーや異常を迅速に検知し、被害を最小限に抑える仕組みが必要です。Amazon CloudWatchと連携し、ジョブの失敗や処理時間の異常な遅延が発生した際に、担当者へ即時アラートを通知する設定を行いましょう。また、一時的なネットワーク障害やAPIの制限などに備え、自動リトライ処理をあらかじめ設計しておくことも、現場の運用負荷を下げるための重要な注意点です。
ポイントの要点整理
安定したデータ連携基盤を長期間維持するためには、開発の初期段階からセキュリティと品質管理の要点を押さえることが成功の鍵です。アクセス権限の適切な管理、データの暗号化、そして自動化された品質チェックと監視体制を組み合わせることで、ビジネスの変化に耐えうる信頼性の高いシステムを実現できます。これらの要点をしっかりと整理し、自社の運用フローへ確実に組み込んでください。
監視体制の確立とコスト最適化
データ連携基盤を構築した後の運用フェーズにおいて、監視体制の確立とコスト最適化は欠かせない基本事項です。AWSのETLアーキテクチャ設計では、開発のスピードだけでなく、長期的な安定稼働を見据えた仕組みづくりが求められます。
監視とコストの判断ポイント
AWS Glue などのマネージドサービスは、実行時間やデータ処理量に応じた従量課金が適用されます。そのため、ジョブの実行時間やリソース使用率を Amazon CloudWatch で常に可視化しておく必要があります。処理要件に対して適切な DPU(データ処理ユニット)が割り当てられているかを定期的に確認し、過剰なリソースを削減することが、AWSのETL環境を最適化するための重要な判断ポイントとなります。
現場運用の注意点と要点
現場で運用する際の注意点として、エラー発生時の迅速な検知と適切なリトライ設計が挙げられます。データの欠損や後続処理への遅延を防ぐため、Amazon SNS を活用したアラート通知の仕組みを必ず設定してください。また、テスト用に起動した開発エンドポイントなどは、稼働しているだけでコストが発生します。消し忘れは予期せぬコスト増大を招くため、タグ付けによるリソース管理を徹底することが重要です。
パフォーマンスの維持と無駄なコストの削減を継続的に両立させることが、運用フェーズにおける最大の要点となります。
まとめ
本記事では、AWS環境でETL処理を成功させるための6つの重要ポイントを解説しました。データ連携基盤の構築は、単に技術的な実装だけでなく、ビジネス要件に合わせた最適なサービス選定、スケーラビリティとコスト最適化の両立、そして運用を見据えた堅牢な設計が不可欠です。
特に、AWS Glueのようなフルマネージドサービスを核としつつ、Amazon S3、Lambda、CloudWatchなどを適材適所で組み合わせることで、データ量の増加やビジネスの変化に柔軟に対応できる基盤が実現します。エラーハンドリングやセキュリティ対策、継続的な監視とコスト最適化は、長期的な安定稼働とデータ品質の担保に直結します。
これらの秘訣を実践することで、AWSのETLサービスを活用したデータドリブン経営を加速させ、企業のDX推進を強力に後押しできるでしょう。
AWS環境でのETL処理を自社の運用に落とし込むときは、本文で整理した判断基準を順に確認してください。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事

データクレンジングとは?AI精度を高めるツール選び3つの極意【2026年版】
手作業では限界がある膨大なデータ処理を自動化し、品質を担保するデータクレンジングツール。本記事では、自社の課題に合わせた最適なツールの選び方や比較のポイントを解説し、導入実績の豊富な無料・有料のおすすめツールを厳選して紹介します。
データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。

サブスクリプションとは?意味・仕組みと成功事例・LTV最大化8ポイント【2026年版】
年々市場が拡大するサブスクリプションビジネス。単なる「定額制」とは異なるビジネスモデルの真の意味から、成功企業が実践しているLTV(顧客生涯価値)向上や解約防止の秘訣を図解でわかりやすく解説します。

SaaSにおけるLTVの計算方法を8つのポイントで解説!CAC比率で健全な成長へ
SaaSビジネスの健全性を測る上で欠かせない「LTV/CACレシオ(比率)」。LTVの正確な計算式から、顧客獲得単価(CAC)との理想的なバランス「3倍の法則」について、事業計画で失敗しないためのLTVの計算方法を解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。

UI/UXとは?決定的な違いとビジネス効果を高める7つの原則【2026年版】
アプリやWebサービスの成功を左右する「UI/UX」。混同されがちな両者の決定的な違いを明らかにし、ユーザーの満足度を高めてビジネス成果に繋げるためのUI/UXデザインの原則を具体例とともに解説します。