データクレンジングとは?AI精度を高めるツール選び3つの極意【2026年版】
手作業では限界がある膨大なデータ処理を自動化し、品質を担保するデータクレンジングツール。本記事では、自社の課題に合わせた最適なツールの選び方や比較のポイントを解説し、導入実績の豊富な無料・有料のおすすめツールを厳選して紹介します。

データ活用で成果が出ない最大の原因は、分析の土台となるデータ自体が「汚れている」ことです。データクレンジングとは、不正確なデータを整理し、ビジネスで使える状態に整えるプロセスであり、これを怠るとAIやBIツールの導入も無駄に終わります。
本記事では、データドリブン経営を成功させるための具体的な手順と、失敗を避けるための3つのポイントを解説します。自社に最適なデータクレンジングツールの選び方から現場への定着方法まで、データ品質を高めてビジネス成果を最大化するノウハウがわかります。
データクレンジングとは?その重要性と背景
ビジネス環境のデジタル化が加速する中、多くの企業がデータドリブン経営への移行を進めています。顧客データや購買履歴、Webサイトのアクセスログなど、企業が日々蓄積するデータ量は爆発的に増加しました。しかし、システムごとにデータの入力規則が異なったり、担当者の手入力による表記揺れが発生したりと、不完全で一貫性のないデータが社内に散在しているのが多くの企業の現状です。このような課題を解決するデータクレンジングとは、社内に散在する不正確なデータを修正・統合し、価値ある情報へと昇華させる不可欠なプロセスです。

データ活用における現状と基本事項
企業が蓄積した膨大なデータを価値ある情報に変えるためには、データの品質を担保するプロセスが不可欠です。データベース上に存在する誤記や表記揺れ、重複、欠損などの不備を特定し、ルールに従って修正または削除することで、データの正確性と網গ্性を高める必要があります。
例えば、顧客名簿において「株式会社」と「(株)」、あるいは半角カタカナと全角カタカナが混在していると、同一の取引先を別々の企業としてカウントしてしまう恐れがあります。
このような不整合なデータ(ダーティデータ)を放置したまま、AIによる需要予測やマーケティングオートメーション(MA)ツールへの連携を行うとどうなるでしょうか。誤った分析結果に基づいて経営判断を下してしまったり、同じ顧客に対して複数回同じダイレクトメールを送付してクレームにつながったりと、ビジネス上の重大な損失を招くリスクが高まります。
総務省の「令和3年版 情報通信白書」などでも指摘されている通り、データの収集・蓄積から「活用」へとフェーズを移行する企業が増加する一方で、データ品質の低さがDX(デジタルトランスフォーメーション)推進の大きな障壁となっています。精度の高い意思決定を行い、パーソナライズされた顧客体験を提供するためには、分析の土台となるデータを常にクリーンな状態に保つ取り組みが、あらゆる企業にとって必須となっています。
2026年版ツール導入の判断ポイントと選び方
データ量が少ない初期段階であれば、Excelなどの表計算ソフトを用いて手作業で整えることも可能です。しかし、数十万件に及ぶデータや複数システムからリアルタイムで流入するデータを扱う場合、手作業は現実的ではありません。そこで必要になるのが、専用の データクレンジングツール の活用です。2026年現在では、AIや機械学習を活用して高度な名寄せや表記揺れ補正を自動化するツールがトレンドとなっています。
ツール導入を判断する重要なポイントは、「データ処理にかかる人的工数」と「データ品質低下によるビジネスインパクト」のバランスです。レポート作成の前にデータ整理だけで数十時間が奪われている場合は、早期の導入を検討すべきサインと言えます。
導入の際、初期費用を抑えるためにデータクレンジングツールを無料で試せる製品や、オープンソース(例: OpenRefineなど)から試験的に始める企業も少なくありません。オープンソースのツールは小規模なデータ処理には適していますが、エンタープライズ規模の基幹システム連携や、高度な日本語の表記揺れ(旧字体・新字体の統一など)を求める場合、機能制限の壁に直面します。そのため、本格的な運用には「Talend Data Fabric」や「Precisely Trillium」といった、機能とサポートが充実した有料ツールの導入が推奨されます。
【2026年版】代表的なデータクレンジングツールの具体例と特徴
| ツール分類 | 代表的な製品名 | 特徴・おすすめの活用シーン |
|---|---|---|
| 無料・オープンソース | OpenRefine | コストをかけずにデータクレンジングツールを無料で試したい企業向け。小規模データの整理やフォーマット変換に強み。 |
| クラウドベース(AWS) | AWS Glue DataBrew | AWS環境を利用しており、コードを書かずに視覚的な操作でデータを準備・クレンジングしたい企業に最適。 |
| エンタープライズ(有料) | Talend Data Fabric | 膨大なデータソースを統合し、高度な品質管理とガバナンスを実現したい大規模プロジェクト向け。 |
| 高度な日本語対応(有料) | Precisely Trillium | 日本語特有の複雑な表記揺れ(全角半角、旧字体、法人格など)や住所正規化に高い精度を誇る。 |
自社の要件を見極める際は、以下の3点を確認してください。
- 対応するデータソースの多様性: 自社で利用しているCRMやSFA、クラウド上のデータベースとスムーズにAPI連携できるか。
- 自動化の精度とAI機能: 独自の業界用語や表記揺れに対し、AIが文脈を判断して自動補正・学習する機能が備わっているか。
- 現場での操作性: プログラミングの専門知識がない事業部門の担当者でも、直感的に設定や運用ができるUIを備えているか。
これらを総合的に評価し、無料ツールのPoC(概念実証)を経てから、自社に最適なツールを選定することが重要です。
現場で運用する際の注意点と定着のコツ
データクレンジングは、一度ツールを導入して過去の蓄積データをきれいにすれば完了するものではありません。日々の業務を通じて新しいデータが絶えず生成されるため、継続的にデータ品質を維持・向上させる運用体制の構築が不可欠です。現場で運用を定着させるためには、いくつか注意すべき重要なポイントがあります。
第一に、データ入力の入り口となるルールの統一とシステム的な制御です。クレンジングツールは強力な武器ですが、そもそも入力段階でエラーを防ぐ仕組みがあれば、後工程の処理負担は大幅に軽減されます。入力フォームのバリデーション(入力チェック機能)を厳格化し、全角・半角の指定や郵便番号からの住所自動入力、必須項目の設定を見直すなど、業務システム側の改修と並行して進めることが最も効果的です。
第二に、運用ルールや判断基準の属人化を防ぐことです。「どのシステムのデータを正(マスター)とするか」「重複する顧客データを発見した際、どちらのレコードを優先して残すか」といった名寄せの判断基準が、特定の担当者の頭の中にしかない状態は非常に危険です。データの統合ルールや辞書の更新手順を明確にドキュメント化し、関係する全部門間で共有・合意する仕組みを整えてください。
第三に、データ品質向上の取り組みを、全社的なIT戦略やデータガバナンス方針の中に正しく位置づけることです。部門ごとに場当たり的なデータ処理やツールの個別導入を行っていると、最終的に経営層が求める統合的なデータ分析が実現できず、いわゆる「データのサイロ化」を助長してしまいます。全体最適を見据えたシステム連携やデータ基盤の設計については、 IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイント を参考に、自社の中長期的なITロードマップと整合性を持たせながら推進することが成功の鍵となります。
データは現代の企業にとって最も重要な資産の一つですが、適切な手入れを怠れば、維持コストばかりがかさむ負債にもなり得ます。現状の課題を正確に把握し、自社に合ったツールと強固な運用体制を組み合わせることで、初めてデータはその真価を発揮し、ビジネス変革の強力な推進力となるのです。
データクレンジングを進める手順

データ品質が低いままAIやBIツールを導入しても、誤った分析結果が出力され、かえって現場の混乱を招きます。組織としてデータクレンジングとは単なるデータ整理ではなく、ビジネスの基盤を強化する戦略的投資であると認識し、場当たり的な修正ではなく体系的なアプローチで進める必要があります。ここでは、具体的な4つの手順と、成功に導くための判断ポイントを解説します。
手順1:現状のデータ品質の評価と目的の定義
まずは、自社が保有するデータの現状を正確に把握し、クレンジングを行う目的を明確に定義します。顧客管理システム(CRM)や営業支援システム(SFA)、基幹システムなどに散在するデータが、どの程度汚れているかを可視化する「データプロファイリング」を実施します。
目的が「マーケティングオートメーション(MA)でのパーソナライズ配信」なのか、「需要予測AIの精度向上」なのかによって、優先的に整えるべきデータの項目と基準が大きく変わります。例えば、新規事業のターゲット市場を分析する場合、顧客の業種や企業規模といった属性データが正確でなければ、致命的な判断ミスを引き起こします。新規事業の立ち上げやデータ活用において、社内リソースだけで推進するのが難しい場合は、コンサルティングサービスを活用して自走化を目指すことも有効な手段です。【2026年版】新規事業のアイデアが思いつかない?コンサル活用で立ち上げの「きつい」を乗り越える3ステップと自走化手順
手順2:クレンジングのルール策定と判断ポイント
データ品質の現状と目的が明確になったら、具体的な修正ルールを策定します。ここで重要なのは、現場の業務プロセスに即した一貫性のある基準を設けることです。
- 表記揺れの統一: 「株式会社」と「(株)」、全角と半角、ハイフンの有無など、企業名や住所の表記ルールを標準化します。
- 欠損値の補完: 必須項目に空欄がある場合、一律で「不明」とするか、外部の企業データベースと照合して情報を補完するかを決定します。
- 重複データの統合(名寄せ): 同一顧客が複数回登録されている場合、最新の更新日を持つレコードを正とするか、購買履歴の多い方を残すかといった優先順位を定めます。
この段階で、手作業で対応する範囲とツールで自動化する範囲の判断ポイントを具体化します。データ量が数千件を超える場合や、日々大量のデータが生成される環境では、手作業での対応は現実的ではありません。自社のデータ量、更新頻度、そして許容できるエラー率を基準に、専用システムの導入を検討してください。
手順3:データクレンジングツールの選定と実行
ルールが固まったら、実際のクレンジング作業を実行します。膨大なデータを効率的かつ正確に処理するためには、データクレンジングツールの活用が不可欠です。
ツールを選定する際は、自社の既存システムとの連携性(APIの有無など)や、設定した独自のクレンジングルールを柔軟に反映できる機能が備わっているかを確認します。コストを抑えてスモールスタートを切りたい場合は、データクレンジングツールを無料で試せるプランやトライアル版を提供している製品を活用し、操作性や処理精度を検証するのが効果的です。
無料ツールを用いて一部のデータセットで基本的な名寄せや表記統一の効果を確認し、その費用対効果を経営層に提示することで、本格的なエンタープライズ向けツール導入の稟議をスムーズに進めることができます。投資リスクを最小限に抑えつつ、確実な成果を積み上げることがプロジェクト成功の鍵です。
手順4:現場での運用と継続的な品質管理
一度データをきれいにしても、日々の業務で新たなデータが入力されれば、再び品質は低下します。データクレンジングは単発のプロジェクトではなく、継続的な運用プロセスとして現場に定着させることが極めて重要です。
現場で運用する際の最大の注意点は、入力段階でのエラーを未然に防ぐ仕組みづくりです。入力フォームの選択式への変更、郵便番号からの住所自動入力機能の実装、さらには入力時にリアルタイムでエラーを検知するバリデーション機能の追加など、システム側で表記揺れを物理的に防ぐ対策を講じます。
また、データ入力を行う営業担当者やカスタマーサポート担当者に対して、データ品質がビジネス全体にどのような影響を与えるのかを共有し、マインドセットの変革を促すことも不可欠です。「なぜ正確な入力が必要なのか」を現場が理解し、データ入力の正確性を人事評価の指標に組み込むなどの工夫を行うことで、組織全体のデータリテラシーが向上します。
定期的にデータ品質をモニタリングする責任者(データスチュワード)を配置し、ルールの形骸化を防ぐガバナンス体制を構築してください。継続的な品質管理によって初めて、AI活用や高度なデータドリブン経営に耐えうる強固なデータ基盤が完成します。
データクレンジングで失敗しない3つの極意
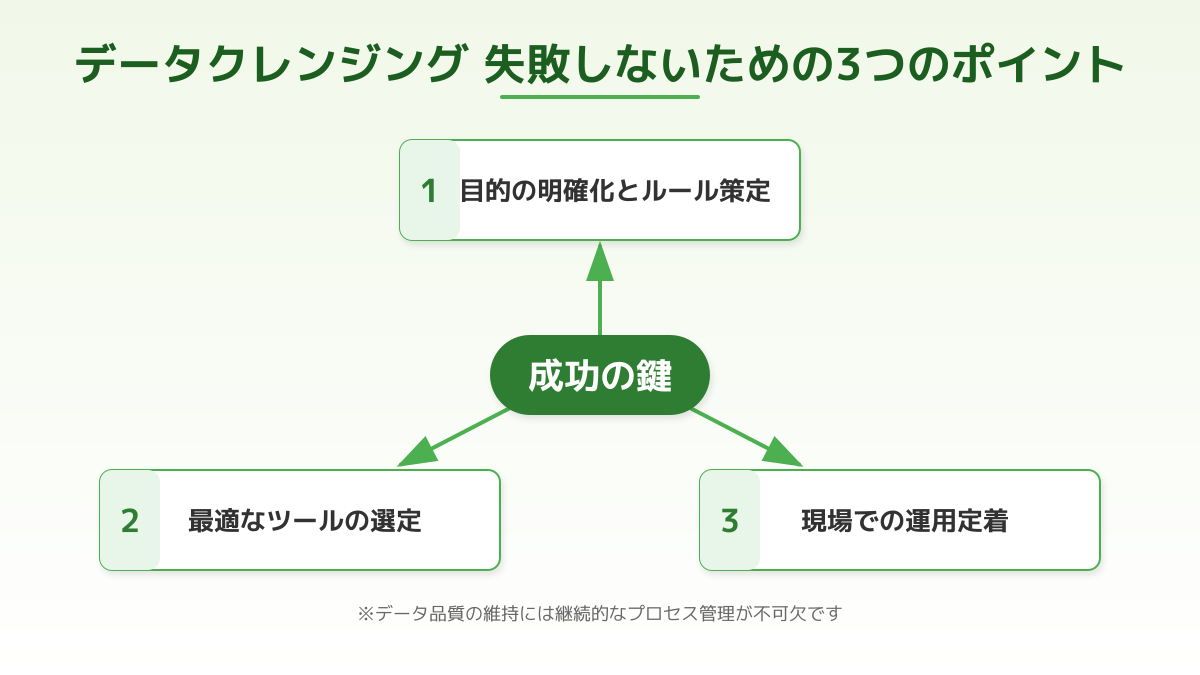
データクレンジングのプロジェクトは、現場の思いつきや場当たり的な対応で進めると、多大な工数とコストをかけたにもかかわらず期待した成果が得られないケースが少なくありません。失敗を防ぐためには、手順やツールの導入だけでなく、組織的な壁を乗り越える戦略的なアプローチが求められます。ここでは、プロジェクトを確実に成功へ導くための3つの極意を解説します。
極意1:スモールスタート(PoC)による費用対効果の検証
全社的なデータ統合を最初から目指すと、プロジェクトが肥大化し、途中で頓挫するリスクが高まります。失敗を避けるための第一の極意は、特定の部署や限定されたデータセット(例えば「過去1年分の優良顧客データのみ」など)を対象に、PoC(概念実証)としてスモールスタートを切ることです。
小さな範囲でデータクレンジングを実施し、「重複データを排除したことでDMの無駄打ちが〇〇円削減できた」「営業のリスト作成時間が〇〇時間短縮された」といった具体的な費用対効果(ROI)を算出します。この小さな成功体験と定量的な成果を経営層に提示することで、その後の全社展開に向けた予算獲得や、本格的なツール導入の稟議がスムーズに進みます。成功率を上げる新規事業フレームワーク実践ガイド で解説しているような、MVP(最小限のプロダクト)を用いた早期検証のアプローチを参考に、小さく始めて確実な成果を積み上げてください。
極意2:部門間の壁を越えるプロジェクト体制の構築
データは営業、マーケティング、カスタマーサポートなど、複数の部門をまたがって生成・利用されます。そのため、情報システム部門単独、あるいは特定の事業部門だけでデータクレンジングを推進しようとすると、「他部署のデータ仕様が分からない」「現場が新しい入力ルールに協力してくれない」といった組織の壁に直面します。
これを防ぐための第二の極意は、各部門から業務とデータの両方に精通したキーパーソンを集め、横断的なプロジェクトチームを組成することです。営業部門には「入力の手間が増える代わりに、正確なターゲットリストが即座に出力できる」といった具体的なメリットを提示し、全社的な協力体制を築きます。データ品質の向上が自部門のKPI達成にどう直結するのかを共有し、利害関係を調整するチェンジマネジメントの視点が成功の鍵を握ります。
極意3:データ品質を評価するKPIの継続的なモニタリング
データクレンジングは「一度綺麗にして終わり」ではありません。プロジェクトの成果を維持するための第三の極意は、データ品質そのものを定量的に評価するKPI(重要業績評価指標)を設定し、定期的にモニタリングする仕組みを作ることです。
例えば、「必須項目の入力完了率(欠損率)」「重複レコードの発生件数」「外部データベースとの照合一致率」などをKPIとして定めます。これらの数値をダッシュボード等で可視化し、品質が一定の基準を下回った場合にはアラートが鳴るような体制を構築します。定期的なモニタリングによって、入力ルールの形骸化や新たなシステムの不具合によるデータの汚れを早期に検知し、データドリブン経営の強固な土台を守り続けることができます。
まとめ
データは現代ビジネスにおける最も重要な資産の一つであり、その品質が企業の意思決定の質を大きく左右します。データクレンジングとは、この重要な資産の価値を最大化し、AI活用やDX推進を成功に導くための生命線です。本記事で解説したように、データクレンジングを成功させるためには、以下の点が重要です。
- 目的の明確化と現状把握: 何のためにクレンジングを行うのか、現状のデータ品質はどうかを正確に定義する。
- 具体的な手順の実行: 評価、定義、ルール策定、ツール選定、実行、そして継続的な改善というサイクルを回す。
- 失敗しないためのポイント: 全社的なルール策定、現場の意識改革、そして適切なツールの選定と運用体制の構築。
データは適切な手入れを怠れば負債となり得ますが、自社に合ったツールと強固な運用体制を組み合わせることで、その真価を発揮し、ビジネス変革の強力な推進力となるでしょう。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事
データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。
データレイクハウスとは?DWH・データレイクとの違いと導入6ポイント【2026年版】
データウェアハウス(DWH)のパフォーマンスとデータレイクの柔軟性を兼ね備えた新しいデータ管理基盤「データレイクハウス」。AIや機械学習の進展に伴いなぜこのアーキテクチャが求められているのか、そのメリットと従来型との決定的な違いを解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。

サブスクリプションとは?意味・仕組みと成功事例・LTV最大化8ポイント【2026年版】
年々市場が拡大するサブスクリプションビジネス。単なる「定額制」とは異なるビジネスモデルの真の意味から、成功企業が実践しているLTV(顧客生涯価値)向上や解約防止の秘訣を図解でわかりやすく解説します。

BPO事業とは?市場規模と戦略的活用で変革を加速する実践ガイド【2026年版】
年々市場規模が拡大しているBPO事業。そもそもBPO事業とはどのようなビジネスモデルなのか、提供されるサービスの種類や急成長の背景を解説します。また、外部委託を検討する企業に向けて、自社の課題に最適なBPOサービスの選び方や、ビジネス変革を加速させた具体的な成功事例を提示します。

システム運用の業務一覧と設計8ポイント|安定稼働を実現するサンプル付【2026年版】
システム開発の終盤で軽視されがちな「システム運用設計」。リリース後の安定稼働とトラブル対応の質はここで決まります。本記事では運用設計の基本概念から、網羅すべき必須の項目、現場で役立つシステム運用の業務一覧の作成方法までを実践的に解説します。