データレイクハウスとは?DWH・データレイクとの違いと導入6ポイント【2026年版】
データウェアハウス(DWH)のパフォーマンスとデータレイクの柔軟性を兼ね備えた新しいデータ管理基盤「データレイクハウス」。AIや機械学習の進展に伴いなぜこのアーキテクチャが求められているのか、そのメリットと従来型との決定的な違いを解説します。
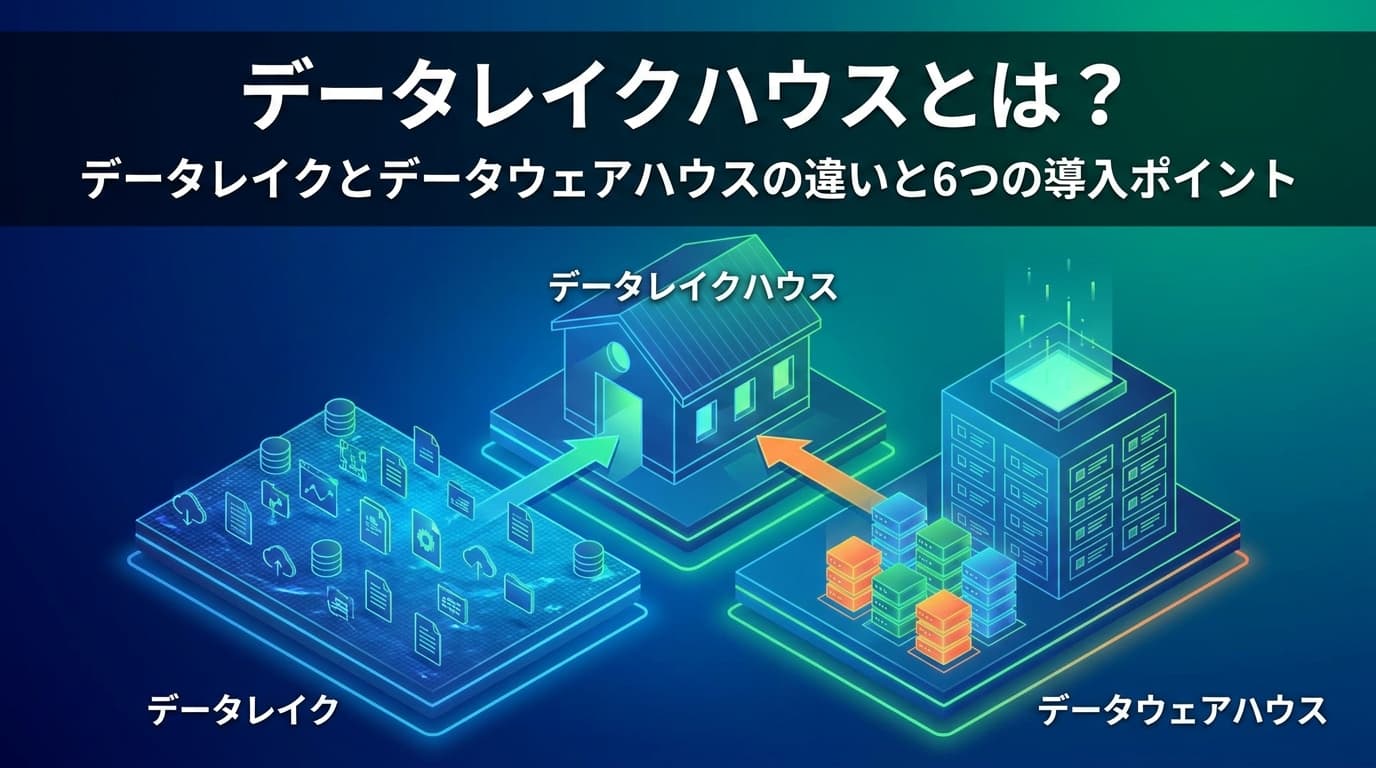
企業のデータ活用において、データレイクとデータウェアハウスの使い分けによるデータのサイロ化や、データ連携・抽出にかかる時間の増大は、意思決定を遅らせる大きな要因です。この課題を解決し、リアルタイムなデータ分析とAI活用を単一基盤で実現する次世代アーキテクチャが「データレイクハウス」です。
本記事では、データレイクハウスとは何かという基本概念から、導入を成功に導く6つの重要ポイント、そしてDatabricksやSnowflakeを用いた具体的なアーキテクチャ事例までを徹底解説します。
データレイクハウスとは?
データレイクハウスとは、データレイクの「柔軟性・低コスト」と、データウェアハウス(DWH)の「データ管理機能・パフォーマンス」を兼ね備えた新しいデータ管理基盤です。
これまで多くの企業は、構造化データを高速に分析するためのデータウェアハウスと、画像やログファイルなどの非構造化データを大量に保存するためのデータレイクを使い分けてきました。しかし、この二重構造はデータのサイロ化や、データ移動に伴うコスト・工数の増大という深刻な課題を生み出していました。
データレイクハウスは、これら2つの基盤の利点を単一のシステムに統合し、BIツールによる定型的な分析から、AI・機械学習を用いた高度な予測までを一つのプラットフォームで実現します。
1. データレイクとデータウェアハウスの課題を解決
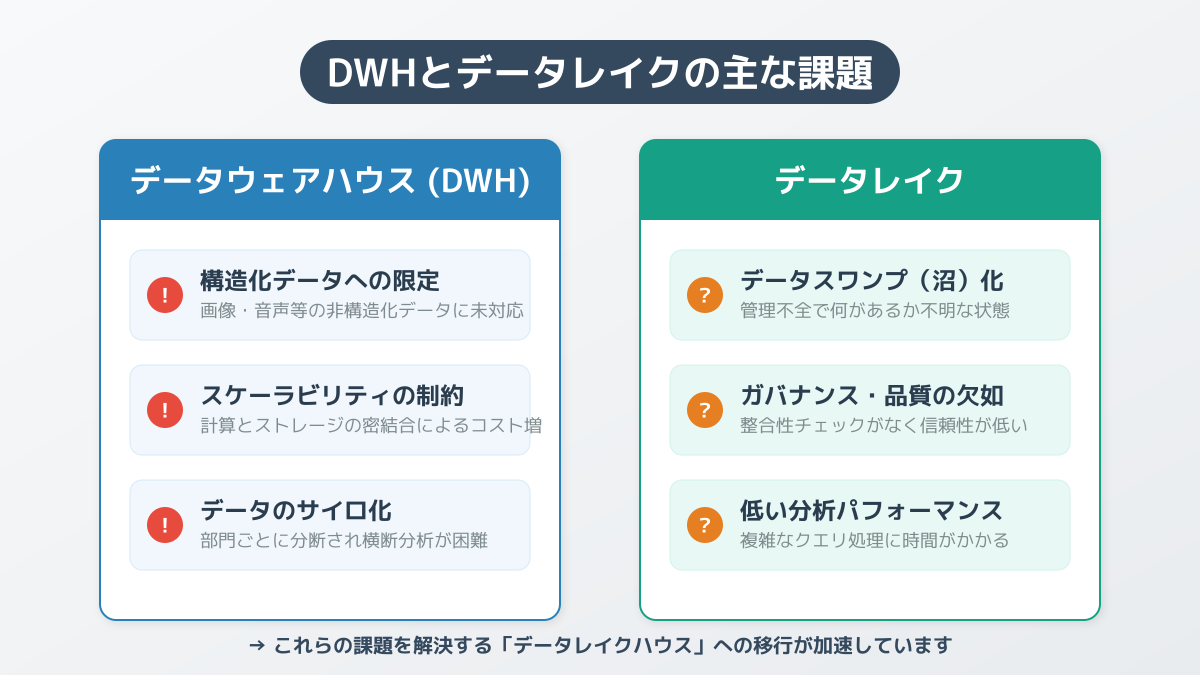
従来のデータ基盤における最大のボトルネックは、データレイクとデータウェアハウス間でデータを移動させるETL(抽出・変換・書き出し)処理に多大な時間がかかることでした。これにより、経営層や現場が求める「鮮度の高いデータ」を即座に提供できないという問題が発生していました。
データレイクハウスは、安価なクラウドストレージ上に直接トランザクション管理層を設けることで、データを移動させることなく直接クエリを実行できるようにします。これにより、データ抽出から分析までのリードタイムが劇的に短縮され、運用コストとエンジニアの負荷を大幅に削減できます。
こうしたデータ基盤の刷新は、場当たり的な対応ではなく、全社的なIT戦略に基づいて計画することが不可欠です。戦略の策定については、 IT戦略マップの作り方と実践的フレームワーク|成功に導く8つの策定ポイント も併せて参考にしてください。
2. ACIDトランザクションによるデータ品質の担保
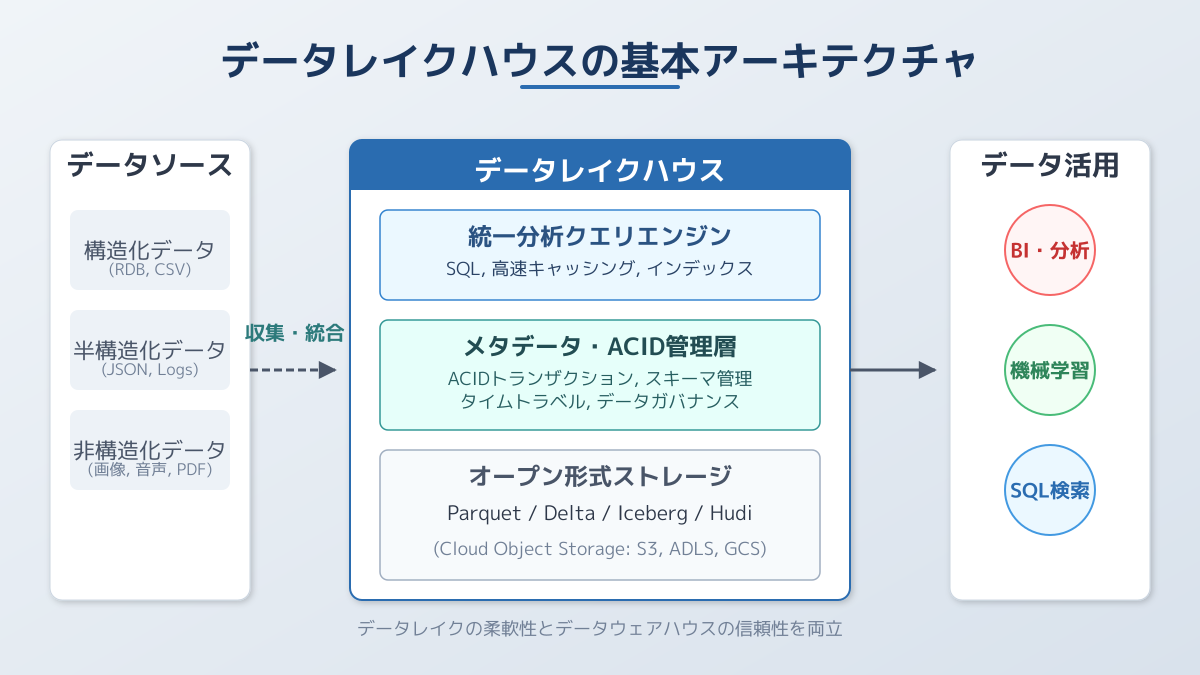
データレイクハウスの最大のブレイクスルーは、安価なオブジェクトストレージ上のデータに対して、データウェアハウスと同等の ACIDトランザクション (原子性、一貫性、独立性、永続性)をもたらした点です。
従来のデータレイク環境では、複数ユーザーによる同時書き込みやデータの更新・削除が頻繁に発生すると、データの不整合が起きやすく、信頼性が低くてビジネスの意思決定に使えない「データスワンプ(データの沼)」に陥るケースがありました。
データレイクハウスでは、メタデータを管理するトランザクション層を設けることで、データ更新時の整合性が完全に保証されます。これにより、データの欠損や重複といった運用上のトラブルを防ぎ、エンタープライズ水準のデータ品質を維持できます。
3. 構造化・非構造化データを統合するガバナンス
データレイクハウスは、構造化データから非構造化データ(画像、テキスト、ログデータなど)まで、あらゆるデータを一元的に蓄積しながらも、厳密なデータ管理を実現します。
現場で運用・定着させるためには、技術面だけでなく組織的な運用ルールの整備が不可欠です。データがどこから生成され、どのような加工が施され、誰がアクセス権を持っているのかという「データリネージ(データの来歴)」を可視化するデータカタログの整備が求められます。
常に「信頼できる単一の情報源(Single Source of Truth)」を提供することで、データエンジニア、データサイエンティスト、ビジネス部門のアナリストが同じデータを参照し、矛盾のない分析結果を共有できるようになります。
4. BIからAI・機械学習まで対応する柔軟なワークロード

従来のアーキテクチャでは、BIツールを用いた定型レポートにはデータウェアハウスを、機械学習などの高度な分析にはデータレイクを使い分ける必要がありました。データレイクハウスは、単一の基盤でこれら両方のワークロードに対応します。
過去の実績を振り返るBI分析から、未来を予測するAI・機械学習まで、異なる目的を持つチームが同じデータをコピーすることなく直接参照できます。データを移動させるための複雑なパイプラインが不要になるため、開発および運用コストが劇的に削減されます。
もしデータ活用を起点とした新規事業の立ち上げに課題を感じている場合は、【2026年版】新規事業のアイデアが思いつかない?コンサル活用で立ち上げの「きつい」を乗り越える3ステップと自走化手順 も合わせて参考にしてください。
5. 細やかなアクセス制御とセキュリティの一元化
データ分析基盤を統合する上で、避けて通れないのがセキュリティと権限管理です。従来のアーキテクチャでは、データレイクとデータウェアハウスが分断されていたため、それぞれで独立してアクセス権限や監査ログを管理する必要があり、設定漏れによる重大なセキュリティリスクを招く原因となっていました。
データレイクハウスでは、すべてのデータに対するアクセス制御、マスキング、監査ログの取得といったセキュリティポリシーを、システム全体に対して一貫して適用できます。
役割に応じたロールベースのアクセス制御(RBAC)や、機密データを保護するための動的データマスキング機能を利用することで、情報漏洩のリスクを大幅に低減しつつ、コンプライアンス要件への対応を迅速化することが可能です。
6. オープンフォーマットの採用とベンダーロックイン回避
最後のポイントは、標準的なオープンフォーマットの採用です。従来のデータウェアハウスでは、特定のベンダーに依存した独自形式が用いられることが多く、将来的なシステム移行や他ツールとの連携においてコストが膨らむ「ベンダーロックイン」の障壁となっていました。
データレイクハウスでは、Apache Parquetなどのオープンなファイルフォーマットと、Apache IcebergやDelta Lakeといったオープンソースのテーブルフォーマットを組み合わせて利用します。
これにより、特定のベンダーの独自機能に過度に依存することなく、自社の要件に合った様々なコンピュートエンジン(Spark、Presto、Trinoなど)を柔軟に組み合わせて利用することができ、将来の拡張性を確保できます。
具体的なアーキテクチャ事例と成功の鍵
データレイクハウスを実現する代表的なプラットフォームとして、 Databricks や Snowflake が挙げられます。それぞれのアーキテクチャには特徴があり、自社の要件に合わせて選定することが重要です。
- Databricksの事例: オープンソースの「Delta Lake」を中心に構築され、AIや機械学習のワークロードに強みを持ちます。ある製造業の事例では、IoTセンサーから送られる膨大な非構造化データと、基幹システムの構造化データをDatabricks上で統合しました。結果として、データ抽出から分析までのリードタイムが数日から数分へと短縮され、リアルタイムな予知保全システムを実現しています。
- Snowflakeの事例: クラウドネイティブなデータウェアハウスとして誕生しましたが、Apache Icebergなどのオープンフォーマットのサポートを強化し、データレイクハウス領域へと進化しています。コンピュート(処理)とストレージ(保存)が完全に分離されたアーキテクチャにより、同時アクセスが集中してもパフォーマンスが低下しない点が評価され、全社的なデータ共有基盤として多くの企業で採用されています。
企業がこれらのアーキテクチャを導入し成功させるためには、各部門が自由にデータを扱うことによるフォーマットの不整合を防ぐ必要があります。データの書き込みルールやメタデータ管理の基準を明確に定め、継続的に監視するデータガバナンス体制を構築することが成功の鍵です。
まとめ
本記事では、データレイクハウスがなぜ次世代のデータアーキテクチャとして注目されるのか、その6つの重要ポイントに焦点を当てて解説しました。データレイクハウスは、従来のデータレイクとデータウェアハウスが抱えていた課題を統合的に解決し、データ品質の担保、厳格なガバナンス、強固なセキュリティ、そしてオープンフォーマットによる柔軟な拡張性を実現します。
これにより、企業はあらゆるデータを一元的に管理し、データドリブンな意思決定を迅速に行うことが可能になります。導入を成功させるためには、単なる技術導入に留まらず、運用体制の確立やデータガバナンスの徹底が不可欠です。自社のビジネス課題と照らし合わせ、適切なデータレイクハウス基盤を構築することで、企業のDX推進とビジネス価値の最大化を実現しましょう。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事

データクレンジングとは?AI精度を高めるツール選び3つの極意【2026年版】
手作業では限界がある膨大なデータ処理を自動化し、品質を担保するデータクレンジングツール。本記事では、自社の課題に合わせた最適なツールの選び方や比較のポイントを解説し、導入実績の豊富な無料・有料のおすすめツールを厳選して紹介します。
データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。

サブスクリプションとは?意味・仕組みと成功事例・LTV最大化8ポイント【2026年版】
年々市場が拡大するサブスクリプションビジネス。単なる「定額制」とは異なるビジネスモデルの真の意味から、成功企業が実践しているLTV(顧客生涯価値)向上や解約防止の秘訣を図解でわかりやすく解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。

SaaSにおけるLTVの計算方法を8つのポイントで解説!CAC比率で健全な成長へ
SaaSビジネスの健全性を測る上で欠かせない「LTV/CACレシオ(比率)」。LTVの正確な計算式から、顧客獲得単価(CAC)との理想的なバランス「3倍の法則」について、事業計画で失敗しないためのLTVの計算方法を解説します。

UI/UXとは?決定的な違いとビジネス効果を高める7つの原則【2026年版】
アプリやWebサービスの成功を左右する「UI/UX」。混同されがちな両者の決定的な違いを明らかにし、ユーザーの満足度を高めてビジネス成果に繋げるためのUI/UXデザインの原則を具体例とともに解説します。