機械学習モデルの種類と評価指標とは?ビジネス導入を成功に導く5つの秘訣【2026年版】
機械学習プロジェクトをPoCで終わらせないためには、自社の目的に合った「機械学習モデル」の選定が不可欠です。本記事では、代表的な機械学習モデルの種類と特徴に加え、ビジネス導入を成功に導く5つの秘訣や、精度を測るための評価指標の基礎知識をわかりやすく解説します。

ビジネスでAI技術を活用し、具体的な成果を出すためには、適切な機械学習モデルの選定から運用まで、一貫した戦略が不可欠です。本記事では、機械学習モデルをビジネスに導入する際に押さえるべき5つの重要ポイントを解説します。解決すべき課題の定義から、代表的な機械学習モデルの種類と評価指標、運用時のリスク管理、そして現場への定着化まで、DX推進を担うビジネスリーダーや実務担当者が明日から実践できる具体的なノウハウを提供。この記事を読むことで、PoCで終わらない実用的なAI導入を実現し、データドリブン経営を加速させるためのロードマップを明確に描けるでしょう。
機械学習モデル導入の目的と課題定義
ビジネスにおいてAI技術を導入する際、最初の関門となるのが目的と課題の明確化です。ここでは、プロジェクトを成功に導くための基本事項を整理します。

解決すべきビジネス課題の定義
機械学習モデルの導入において最も重要なのは、「何を予測し、どう分類したいのか」という基本事項の整理です。ビジネス活用においては、単に最新のテクノロジーを導入することが目的化してはいけません。売上予測、製造ラインの異常検知、顧客の離反予測など、解決したい具体的な課題を定義する必要があります。この初期段階での課題設定が、後続のアルゴリズム選択やデータ収集の方向性を決定づけます。
導入可否の判断ポイント
課題が明確になったら、それを本当に機械学習で解決すべきかという判断ポイントを具体化します。確認すべき主な基準は以下の3点です。
- データの有無と質: 予測の根拠となるデータが、十分な量と品質で蓄積されているか
- 費用対効果: 開発および運用にかかるコストを上回るビジネスインパクトが見込めるか
- ルールの複雑さ: 従来のルールベース(単純な条件分岐)のシステムでは対応が困難な、複雑なパターンが存在するか
これらの条件を満たさない場合、無理にAIを採用するのではなく、既存の業務効率化ツールで代替する方が適切なケースも少なくありません。なお、新規事業としてAI導入を進める際、初期コストが障壁となる場合は 【2026年版】新規事業 補助金の完全ガイド|個人事業主・中小企業向け申請手順 などを活用して資金調達を検討するのも有効な手段です。
現場で運用する際の注意点
機械学習モデルを実際の現場で運用する際の注意点として、予測精度が時間とともに低下する「データドリフト」への対応が挙げられます。市場環境や顧客行動の変化により、過去のデータで学習したモデルは徐々に現状と乖離していきます。そのため、導入して終わりではなく、定期的な再学習と精度のモニタリング体制をあらかじめ構築しておくことが不可欠です。
要点の整理
このセクションの要点を整理すると、以下のようになります。
- 解決すべきビジネス課題を具体的に定義する
- データ基盤と費用対効果の観点から導入の妥当性を厳しく判断する
- 運用開始後の精度維持(再学習)を見据えた体制を準備する
これらの要点を押さえることで、テクノロジーの導入を単なる実証実験(PoC)で終わらせず、実際の業務プロセスへ確実に定着させることが可能になります。
代表的な機械学習モデルの種類と選び方
機械学習モデルを実際のビジネスに導入する際、2つ目の重要なポイントとなるのが「解決したい課題に合わせた適切なモデルの選定」です。自社の目的に合致しないアプローチを選んでしまうと、どれほど高品質なデータを準備しても期待する成果は得られません。ここでは、代表的な機械学習モデルの種類と、実務における判断基準や運用時の注意点について整理します。
課題解決の鍵となる3つのアプローチと代表的なアルゴリズム
機械学習モデルの種類は、大きく「教師あり学習」「教師なし学習」「強化学習」などに分けられ、さらに出力する結果の性質によって細分化されます。ビジネス現場で頻繁に活用される代表的なアプローチは、 回帰 、 分類 、および クラスタリング の3つです。
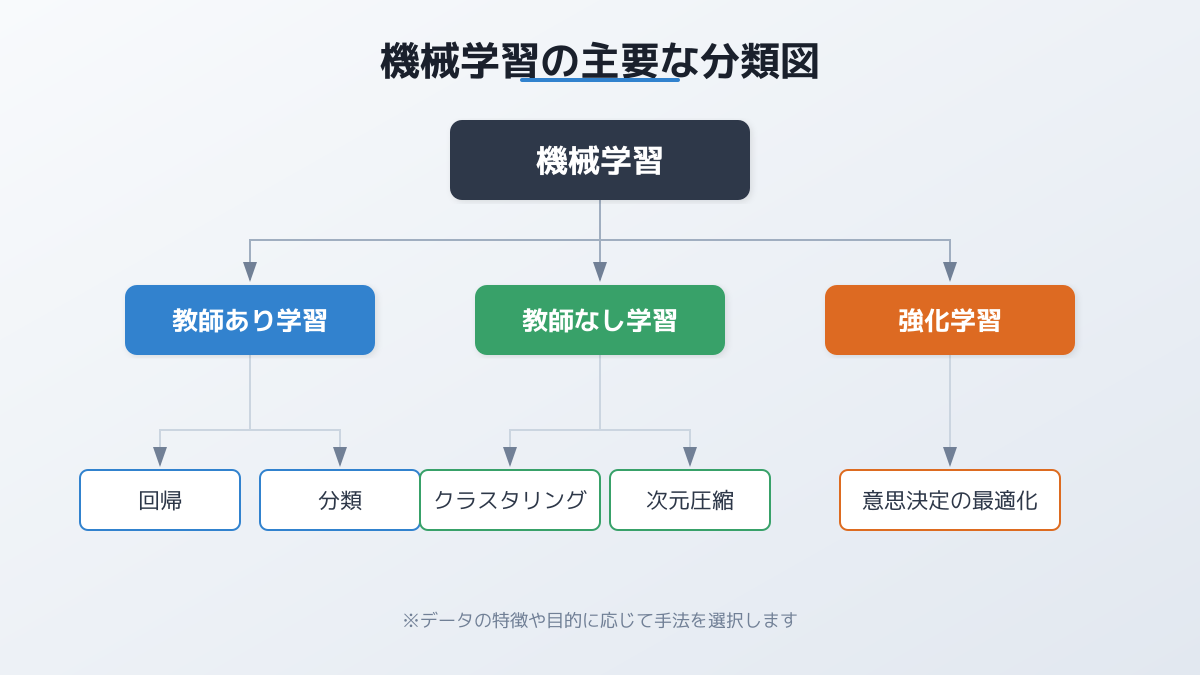
回帰 は、過去のデータをもとに連続する数値を予測する手法です。例えば、来月の店舗売上や、製品の需要予測、プロモーションに対する投資対効果(ROI)の算出などに用いられます。具体的なアルゴリズムとして「線形回帰」や、非線形な予測に強い「ランダムフォレスト回帰」「LightGBM」などがあり、将来の数値を定量的に把握することで、在庫管理の最適化や予算配分の精度向上が期待できます。
一方、 分類 は、データがどのカテゴリに属するかを予測する手法です。スパムメールの判定や、顧客がサービスを退会するかどうかの離反予測、製造ラインにおける製品の不良品検知などが該当します。アルゴリズムとしては「ロジスティック回帰」「サポートベクターマシン(SVM)」や、精度の高い「XGBoost」などが活用されます。人手による目視確認や経験則に頼っていた判断プロセスを自動化し、業務の効率化と品質の均一化を実現します。
そして クラスタリング は、正解データを与えずに、データ同士の類似性に基づいて自動的にグループ分けを行う手法(教師なし学習)です。膨大な購買履歴をもとにした顧客セグメンテーションや、通常のパターンから外れた異常値の検出などに使われます。代表的なアルゴリズムである「K-means法」や「階層的クラスタリング」を活用することで、データに潜む新たなパターンやインサイトを発見する際に力を発揮します。
最適なモデルを選ぶための判断ポイント
実務においてどのモデルを採用すべきか迷った際は、以下の判断ポイントを具体化することが重要です。
第一に「予測したい対象は何か」を明確にします。具体的な数値を導き出したいのであれば回帰モデルを、特定のカテゴリに振り分けたいのであれば分類モデルを選択します。
第二に「学習用の正解データ(ラベル)が十分に存在するか」を確認します。過去の業務システムに蓄積されたデータに明確な正解(例:過去の売上実績や退会履歴など)が含まれていれば教師あり学習が適用できますが、正解がない状態から傾向を掴みたい場合は、教師なし学習であるクラスタリングなどを選ぶことになります。
また、予測精度と解釈性のバランスも重要な判断基準です。ディープラーニングのような複雑なモデルは高い精度を誇りますが、なぜその予測結果になったのかを人間が理解しにくいというブラックボックス化の課題があります。経営層や現場の担当者に結果の根拠を論理的に説明する必要がある業務では、精度がやや劣っても解釈性の高いシンプルなモデルを選ぶ方が、結果的にプロジェクトがスムーズに進むケースが多々あります。
現場で運用する際の注意点
機械学習モデルを実際の業務プロセスに組み込み、継続的に運用する際の注意点も押さえておく必要があります。
まず、モデルは一度構築して終わりではありません。市場環境や顧客の行動様式が変化すると、過去のデータで学習したモデルの予測精度は徐々に低下します。これを防ぐためには、定期的に最新のデータを読み込ませてモデルの精度を監視・再学習させる仕組みを構築し、継続的な改善サイクルを回すことが不可欠です。
さらに、テクノロジーの導入自体を目的化しない視点も求められます。機械学習モデルはあくまで業務効率化や新規ビジネス創出を実現するための手段の1つです。モデルが弾き出した予測結果を、現場の担当者がどのように解釈し、具体的なアクション(例えば、離反しそうな顧客への特別オファーの送信など)に繋げるのか、業務フロー全体を見直す必要があります。こうしたプロセスは、企業全体のデジタル変革の取り組みと密接に関わっています。基礎的なデジタル化の概念や推進手順については、【2026年版】デジタル化とは簡単に言うと?DX化との違いやデメリット・推進手順を完全ガイド を参考に、自社の現在地を確認しておくことをおすすめします。
要点の整理とビジネスへの適用
ここまで解説した、機械学習モデルの種類と選び方に関する要点を整理します。
ビジネス課題を解決するためには、まず自社の目的が数値予測(回帰)、カテゴリ分け(分類)、あるいはグループ化(クラスタリング)のどれに該当するのかを見極めることが第一歩です。その上で、データの有無や業務で求められる説明責任の度合いに応じて、最適なモデルを選択します。
また、運用フェーズにおいては、精度の劣化を監視する体制づくりと、予測結果を実際のビジネスアクションに落とし込むための業務プロセスの再設計が不可欠です。これらの要点をしっかりと押さえることで、機械学習モデルは単なるPoC(概念実証)にとどまらず、企業のデータドリブン経営を支え、中長期的な競争力を高める強力な武器として機能します。
機械学習モデルの評価指標と判断基準
ビジネスに機械学習モデルを導入する際、単に「AIが予測を出力する」だけでは不十分です。その予測がビジネスの目的に対してどれほど有用かを正しく測る必要があります。ここでは、機械学習モデルの評価指標に関する基本事項と、現場での判断ポイントについて整理します。
精度を正しく測る代表的な指標と特徴
モデルの性能を客観的に評価するためには、目的に合った評価指標を理解することが不可欠です。分類問題においてよく使われる代表的な指標には、精度(Accuracy)、適合率(Precision)、再現率(Recall)などがあります。
- 精度(Accuracy) :すべての予測の中で、正解した割合を示します。直感的に分かりやすい指標ですが、データに偏りがある場合はすべて「正常」と予測するだけで数値が高くなるため注意が必要です。
- 適合率(Precision) :モデルが「正」と予測したもののうち、実際に「正」であった割合です。誤検知を減らしたい場合に重視されます。
- 再現率(Recall) :実際に「正」であるもののうち、モデルが正しく「正」と予測できた割合です。見逃しを防ぎたい場合に重視されます。
以下の表に、代表的な評価指標の比較をまとめます。
| 指標名 | 意味 | ビジネスでの活用例 | 重視すべきケース |
|---|---|---|---|
| 精度 (Accuracy) | 全体のうち予測が当たった割合 | 一般的なアンケート分析や需要予測 | データのクラス割合が均等な場合 |
| 適合率 (Precision) | 「正」と予測した中の正解率 | スパムメール判定、おすすめ商品の提案 | 誤った予測によるペナルティが大きい場合 |
| 再現率 (Recall) | 実際の「正」を見つけ出せた割合 | 不良品検知、病気の診断、不正検知 | 見逃しによる損失が極めて大きい場合 |
| F値 (F1-score) | 適合率と再現率の調和平均 | 顧客の離反予測、ターゲティング広告 | 適合率と再現率のバランスを取りたい場合 |
ビジネス課題に応じた判断ポイントの具体化
機械学習モデルを評価する際、どの指標を最優先すべきかは、解決したいビジネス課題によって異なります。ここでの判断ポイントは、 適合率 と 再現率 のトレードオフ関係を理解し、自社のビジネスリスクと照らし合わせることです。
たとえば、製造業における工場の不良品検知システムを構築する場合を考えてみましょう。このケースでは、不良品を正常品として出荷してしまう(見逃し)と、大規模なリコールや信用の失墜につながります。そのため、多少の正常品を「不良品かもしれない」と誤検知して人間が再確認する手間が増えたとしても、不良品を確実に見つけ出す 再現率 を高く設定するべきです。
一方で、マーケティングにおけるスパムメール判定や、顧客への商品レコメンド機能では状況が異なります。正常なメールをスパムとしてゴミ箱に入れてしまうと、重要なビジネス機会を損失する恐れがあります。
このような場合は、確実にスパムであるものだけを弾くために 適合率 を重視するのが適切な判断です。機械学習モデルの判断ポイントを具体化する際は、このように「誤検知」と「見逃し」のどちらがビジネスへのダメージが大きいかを関係者間で合意しておくことが重要です。
現場で運用する際の注意点と要点の整理
評価指標を実際の現場で運用する際の注意点をまとめます。テスト環境でどれほど高い評価指標を達成したとしても、実際のビジネス現場で期待通りの効果が出るとは限りません。
第一に、評価指標の数値だけを追うのではなく、最終的なビジネスインパクト(コスト削減額、売上増加、作業時間の短縮など)と結びつけて評価を整理することが重要です。モデルの精度を1%向上させるために莫大な計算コストや開発期間がかかる場合、投資対効果(ROI)の観点からそのモデルの運用が適切ではないと判断されることもあります。
第二に、運用開始後の「データドリフト」に注意する必要があります。市場のトレンドや顧客の行動パターンは時間の経過とともに変化するため、過去のデータで学習した機械学習モデルの性能は徐々に劣化していきます。
そのため、現場で運用する際は、定期的にモデルの予測結果と実際の正解データを照らし合わせる必要があります。精度や適合率が一定の基準を下回っていないかを監視する仕組みが不可欠です。
このように、運用時の要点を押さえるためには、3つのステップを総合的に管理することが求められます。目的に応じた適切な評価指標の選定、ビジネスリスクに基づく判断基準の明確化、そして運用後の継続的なモニタリング体制の構築です。
運用時のリスク管理とデータバイアス対策

機械学習モデルをビジネスの現場で運用する際、予測精度だけでなく「未知のデータへの対応力」と「公平性」が重要な判断ポイントになります。ここでは、運用時のリスク管理という観点から基本事項を整理します。
過学習とデータバイアスのリスク
モデル構築で最も注意すべき課題が 過学習(オーバフィッティング) です。これは、訓練データに過剰に適合し、本番環境の新しいデータに対して予測精度が著しく低下する現象です。過学習を防ぐには、交差検証などの手法が不可欠です。
また、学習データ自体に偏りがある場合は データバイアス が生じます。特定の属性に偏った過去データで学習させると、新規ターゲット層に対して不適切な予測結果を出力するリスクが高まります。
現場運用における判断ポイントと注意点
機械学習モデルを現場に定着させるためには、以下の要点を押さえておく必要があります。
- 定期的なモニタリング: ビジネス環境の変化に伴い、データの傾向は日々変化します。予測結果と実績を定期的に比較し、モデルの劣化を早期に検知する仕組みを構築します。
- 再学習の基準設定: 精度低下が起きた際、どのタイミングで新しいデータを用いてモデルを更新するか、明確な判断ポイントを定めておきます。
- 結果の解釈性: 実務担当者が納得して活用できるよう、なぜその予測に至ったのかを説明できる仕組みの採用も検討します。
これらの要点を整理し、技術的な精度と実用性のバランスを取ることが重要です。
現場への定着化と継続的な運用体制
機械学習モデルをビジネスに導入する際、開発完了がゴールではありません。実際の業務環境に組み込み、継続的に価値を生み出す運用フェーズへの移行が不可欠です。ここでは、実運用を見据えた評価と定着化の要点を整理します。
ビジネス要件に基づく判断ポイントの具体化
現場で活用する機械学習モデルを選定する際は、単なる予測精度の高さだけでなく、推論速度や運用コスト、結果の解釈性が自社のビジネス要件と一致しているかを判断ポイントとして具体化する必要があります。たとえば、リアルタイム性が求められるシステムでは、わずかな精度向上よりも応答速度を優先すべきケースがあります。また、現場の担当者が「なぜその予測が出たのか」を納得できる説明可能性も、業務への定着を左右する重要な要素です。
現場運用の注意点と継続的な精度維持
現場で運用する際の最大の注意点は、市場環境や顧客行動の変化によって予測精度が徐々に低下する「データドリフト」と呼ばれる現象です。これを防ぐためには、定期的なデータの再学習と監視体制を構築することが要点となります。
技術的な評価指標の監視にとどまらず、その機械学習モデルが実際のビジネスKPI(売上向上や工数削減など)にどのような影響を与えているかを継続的にモニタリングしてください。現場が予測結果を正しく解釈し、無理なく日々の業務プロセスに組み込める運用フローを設計することが重要です。
まとめ
本記事では、ビジネスで機械学習モデルを成功裏に導入・運用するための5つの重要ポイントを解説しました。まず、解決すべきビジネス課題を明確に定義し、その上で目的とデータ特性に合わせた適切なモデル(回帰、分類、クラスタリングなど)を選定することが不可欠です。次に、モデルの性能を正しく測るための評価指標(精度、適合率、再現率など)を理解し、ビジネスリスクに応じた判断基準を設ける必要があります。さらに、過学習やデータバイアスといった運用時のリスクを管理し、継続的な精度維持のための再学習体制を構築することが重要です。これらのポイントを総合的に実践することで、PoCで終わらない実用的なAI導入を実現し、企業のDX推進と競争力強化に貢献できるでしょう。


鈴木 雄大
大手SIerおよびコンサルティングファームを経て独立し、現在は企業のデジタルトランスフォーメーション推進を支援する専門家。これまでに数十社以上の基幹システム刷新や新規デジタル事業の立ち上げを主導してきた。DXナビでは、現場で培った実践的なノウハウと最新のテクノロジートレンドを分かりやすく解説する。真のビジネス変革を目指すリーダーに向けた情報発信に注力している。
関連記事
データクレンジングとは?AI精度を劇的に高める5つのやり方と失敗しない運用
データドリブンな意思決定やAI活用において、データの品質は成否を分けます。本記事では、データのノイズや重複を取り除く「データクレンジング」の基礎から、ビジネスにおける重要性、エクセルや専用ツールを用いた実践的な5つのやり方を解説します。

データクレンジングとは?AI精度を高めるツール選び3つの極意【2026年版】
手作業では限界がある膨大なデータ処理を自動化し、品質を担保するデータクレンジングツール。本記事では、自社の課題に合わせた最適なツールの選び方や比較のポイントを解説し、導入実績の豊富な無料・有料のおすすめツールを厳選して紹介します。
プロセスマイニングとは?DX推進を成功に導く8つのポイント【2026年版】
企業の業務プロセス改善において、担当者の感覚に頼らないデータドリブンなアプローチとして注目される「プロセスマイニング」。システム上のログデータを活用して真のボトルネックを特定する仕組みや、DX推進における具体的な導入メリットを解説します。

LLM(大規模言語モデル)とは?生成AIとの違いとビジネス導入5ステップ【2026年版】
ChatGPTなどで注目される大規模言語モデル「LLM」。本記事ではLLMの基本的な仕組みから、従来のAIや生成AIとの違い、2026年最新の技術動向、ビジネス現場での具体的な活用事例まで、経営層や実務担当者に向けてわかりやすく徹底解説します。

SaaSにおけるLTVの計算方法を8つのポイントで解説!CAC比率で健全な成長へ
SaaSビジネスの健全性を測る上で欠かせない「LTV/CACレシオ(比率)」。LTVの正確な計算式から、顧客獲得単価(CAC)との理想的なバランス「3倍の法則」について、事業計画で失敗しないためのLTVの計算方法を解説します。

BPO事業とは?市場規模と戦略的活用で変革を加速する実践ガイド【2026年版】
年々市場規模が拡大しているBPO事業。そもそもBPO事業とはどのようなビジネスモデルなのか、提供されるサービスの種類や急成長の背景を解説します。また、外部委託を検討する企業に向けて、自社の課題に最適なBPOサービスの選び方や、ビジネス変革を加速させた具体的な成功事例を提示します。